
In the realm of natural language processing (NLP), the quest for ever-more sophisticated models capable of understanding and generating human-like text continues unabated. Among the latest advancements is Retrieval-Augmented Generation (RAG), a paradigm that marries the power of large language models (LLMs) with the ability to retrieve and integrate information from vast knowledge sources. Today, we will see what RAG is and how it works to enhance the LLM-powered applications.
Understanding Retrieval-Augmented Generation (RAG)
LLMs have the inherent habit of producing biased, fake or sometimes made up responses. This happens for various reasons and the process is known as LLM hallucination. RAG is an approach to help LLMs retrieve the most accurate responses by helping them mitigate their hallucinations. Here, an external knowledge base is already provided to the AI system to retrieve the information from. This way, LLMs get to the vector databases where the knowledge source is present and retrieve the information needed by the user. This makes the process smooth and proper retrieval happens since there is no chance for LLMs to hallucinate as the external knowledge corpus is already provided. RAG represents a significant leap forward in the realm of NLP, promising enhanced comprehension, context-awareness, and generation capabilities.
How RAG Works?
In a nutshell, this is how RAG works. The user asks a question, the LLM accesses the knowledge base to find the most contextually relevant information and generates a response.
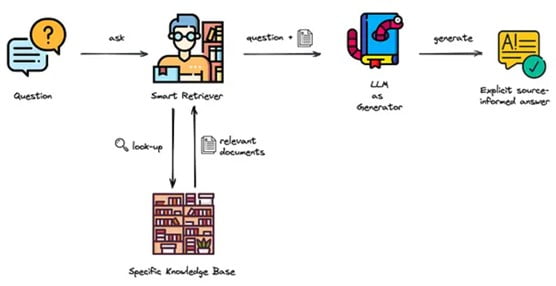
Let’s delve a little deeper into the inner workings of RAG:
Pre-retrieval:
- Understanding the User’s Intent: Before diving into the knowledge base, RAG analyzes the user’s query. This involves techniques like named entity recognition (identifying key terms) and natural language understanding (grasping the overall meaning).
- Formulating a Search Query: Based on the analysis, RAG crafts a specific search query for the knowledge base. This query aims to retrieve the most relevant information that can assist the LLM in generating a response.
Retrieval:
- Scouring the Knowledge Base: RAG interacts with the chosen knowledge base, which could be a vast collection of text documents, databases, or even specialized domain-specific repositories. The search query acts as a guide, helping RAG sift through the information.
- Ranking Relevant Passages: Not all retrieved information is created equal. RAG employs ranking algorithms to identify the passages from the knowledge base that are most pertinent to the user’s query. This ensures the LLM focuses on the most valuable data.
Post-retrieval:
- Information Filtering and Summarization: The retrieved passages might contain unnecessary details. RAG employs filtering techniques to extract the core information required for the LLM’s task. Additionally, summarization techniques can condense lengthy passages into concise snippets, making it easier for the LLM to process.
- Highlighting Key Facts: RAG can identify key facts or entities within the retrieved passages. These highlighted elements provide crucial pieces of information that the LLM can directly integrate into its response.
Generation:
- Empowering the LLM: Armed with the processed information from the knowledge base, RAG presents it to the LLM. This can be done through various methods, like incorporating the retrieved data points into the prompt for the LLM.
- Leveraging the LLM’s Power: With the newfound knowledge, the LLM utilizes its language processing capabilities to generate a response. This response should be accurate, relevant to the user’s query, and potentially cite the retrieved information for transparency.
So, it all starts from a user query and then ends with a proper response from the LLM by retrieving the more accurate information from the vector database where the knowledge base is stored.
Challenges and Advancements of RAG:
While RAG offers significant advantages, there are challenges. The quality and structure of the knowledge base are crucial. Additionally, integrating information from external sources requires careful processing to avoid overwhelming the LLM.
Retrieval Quality: The effectiveness of RAG heavily relies on the quality of the retrieval system. If the retrieval system fails to fetch relevant documents or passages, the generated content may lack accuracy and coherence.
Scalability: As the amount of available data grows, the scalability of the retrieval process becomes a challenge. Efficiently retrieving relevant information from large corpora while maintaining low latency is non-trivial.
Domain Adaptation: RAG models may struggle to adapt to new or specialized domains where training data is limited. Fine-tuning or retraining the retrieval and generation components for specific domains can be resource-intensive.
Biases in Retrieval: Like any information retrieval system, RAG models can be susceptible to biases present in the training data. Biases in the retrieval process can lead to biased or skewed generated content.
Evaluation Metrics: Developing appropriate evaluation metrics for assessing the performance of RAG systems is challenging. Traditional metrics used for natural language generation may not fully capture the effectiveness of the retrieval-augmented approach.
Latency: Real-time applications of RAG, such as chatbots or question answering systems, require low latency responses. Balancing the trade-off between retrieval accuracy and response time is essential for maintaining user satisfaction.
There are several research works happening around RAG to make it more streamlined to use for organizations. Some of the recent works on RAG include Tree-RAG (T-RAG), MultiHop-RAG, Corrective RAG (C-RAG), etc.
Benefits of RAG:
By leveraging the vast expanse of available textual data, RAG enhances the relevance, accuracy, and coherence of generated text. This approach empowers systems to provide contextually rich responses, tailored to the user’s needs and preferences.
There are some notable benefits that RAG has:
- Enhanced Accuracy: By referencing a reliable knowledge base, LLMs are less likely to spout incorrect information.
- Improved Credibility: Users can trust that LLM responses are grounded in facts.
- Domain-Specific Knowledge: RAG allows for integrating specialized knowledge bases, making LLMs more adept at specific tasks.
- Up-to-Date Information: RAG ensures that LLM responses reflect the latest information.
RAG is being utilized by organizations around the globe while building LLM-powered applications such as customer support chatbots, Q&A chatbots, summary generation chatbots, etc. However, RAG isn’t a silver bullet. The quality of the knowledge base is crucial.
But nevertheless, RAG is a significant step forward in making LLMs more reliable and trustworthy. As RAG continues to develop, we can expect LLMs to become even more powerful tools for communication, learning, and problem-solving.
RAG Applications in Production
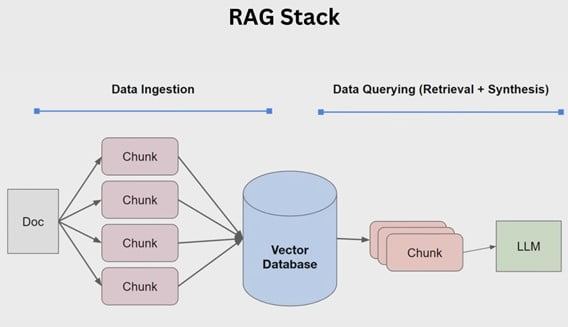
Image source: LlamaIndex
Here’s a breakdown of key aspects to consider for production-ready RAG applications:
Building Production-Grade RAG Systems:
- Collaboration is Key: Building RAG applications for production necessitates input from various specialists. Data scientists assess LLMs for suitability, enterprise AI developers design and test the application, data engineers prepare and manage data for indexing and retrieval, and MLOps/DevOps teams ensure deployment and maintenance.
- Optimizing Performance: Several techniques can enhance RAG application performance in production. These include:
- Decoupling Retrieval and Synthesis: Separating data chunks used for retrieval from those used for LLM generation improves efficiency.
- Structured Retrieval for Large Datasets: For massive datasets, employing structured retrieval methods like passage retrieval can be beneficial.
- Dynamic Retrieval: Adapting the retrieved data chunks based on the specific task can further optimize performance.
Context Embedding Optimization: Optimizing context embeddings used for retrieval can significantly impact the quality of retrieved information.
The journey from a pilot RAG application to a full-fledged production system involves several steps:
- Development: This involves building the core RAG application logic, integrating retrieval and LLM generation components.
- Scaling: Production environments demand scalability. This involves scaling all the major workloads like loading, chunking, embedding, indexing, and serving the application.
- Evaluation: Rigorous evaluation is crucial to identify the optimal configuration for your specific use case. This involves evaluating each component’s performance and the overall application effectiveness.
- Deployment: Finally, the application is deployed in a highly available and scalable manner to ensure continuous operation.
Tools for Developing and Deploying RAG Applications in Production
You need certain tools to develop and deploy the RAG applications. We have identified some commonly used tools and let’s go over them one by one.
Data Preparation and Retrieval:
Data Loaders: Tools like custom scripts or pre-built data loaders can ingest data from various sources and prepare it for processing. Consider tools specific to your data format (e.g., email, documents). You can also choose AI frameworks like LangChain or LlamaIndex.
Vector Databases: Tools like Qdrant, Weaviate, Pinecone, or Faiss enable efficient storage and retrieval of document embeddings used for similarity matching during data retrieval.
Development and Training:
RAG Frameworks: Frameworks like LangChain, LlamaIndex, Haystack, or NVIDIA DeepSpeed offer functionalities for building RAG pipelines, integrating retrieval and LLM generation components.
Open-Source LLMs: Explore open-source LLMs like Llama 3, Mistral, Jurassic-1 Jumbo, BLOOM, etc for cost-effective LLM integration.
Scaling and Deployment:
Containerization Tools: Containerization tools like Docker or Podman can package your RAG application for easy deployment and management across various environments.
Kubernetes: Container orchestration platforms like Kubernetes facilitate deployment and scaling of your containerized RAG application in production.
MLOps Tools: Tools like Kubeflow Pipelines or MLflow can automate the deployment, monitoring, and management of your RAG application in production.
Additional Considerations
Hybrid LLM Routing: Tools like haystack or custom routing logic can be used to manage routing tasks to the most suitable LLM (open-source or closed) based on cost and performance needs.
Monitoring and Logging: Integrate monitoring and logging tools to track application performance, identify errors, and ensure smooth operation.
Remember: These tools are just for your understanding. Specific tools you choose will depend on your unique project requirements, infrastructure, and expertise.
Hope you understood what RAG is and an end to end approach to building and deploying these applications. RAG is going to be the talk of the Gen AI town in the coming days and it’s here to stay and hence it is highly recommended for AI/ML engineers to learn and understand how these applications work. Well, hope we made an authentic effort to spread the impact of RAG and its implications to the world. If you find this article insightful, please share it with your colleagues and friends.
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


