
Large language models (LLMs) have revolutionized the field of natural language processing (NLP), providing impressive capabilities in tasks such as translation, summarization, and conversational AI. However, one persistent issue with LLMs is their tendency to generate “hallucinations”—outputs that are factually incorrect or nonsensical. Addressing these hallucinations is crucial for ensuring the reliability and accuracy of AI systems. One promising strategy to mitigate this problem is Retrieval-Augmented Generation (RAG). In this article, we will explore what LLM hallucinations are, their drawbacks, and various strategies to reduce them, with a detailed focus on the RAG approach.
LLM Hallucination
Hallucination in Large Language Models (LLMs) refers to the generation of responses that are inaccurate or unsupported by the provided context or training data. This is a significant challenge in the deployment of LLMs, particularly in sensitive applications such as healthcare, finance, and legal domains, where inaccurate information can have serious consequences.
While LLMs have impressive capabilities in generating human-like text, they often “make things up” that are factually incorrect or inconsistent. This hallucination behavior undermines the trustworthiness and reliability of these models, limiting their potential in critical real-world applications.
The issue of hallucination is particularly prominent in open-ended generation tasks, such as story completion, dialogue generation, or question-answering, where the models have a high degree of freedom in generating responses. Despite the advances in LLM research, mitigating hallucination remains a complex and challenging task.
Drawbacks of LLM Hallucination
Hallucinations in LLMs can have serious consequences, particularly in applications where accuracy and reliability are paramount. For instance, in the healthcare domain, hallucinated outputs from language models could lead to incorrect diagnoses or treatment recommendations, potentially putting lives at risk. Similarly, in the financial sector, hallucinations could result in erroneous investment advice or financial analyses, leading to significant monetary losses.
- Misinformation and Fake News: Hallucinations can lead to the spread of misinformation and fake news. Inaccurate or made-up facts generated by LLMs can be presented as truth, especially when the models are perceived to be authoritative or knowledgeable. This can have serious societal implications, impacting trust in institutions, influencing public opinion, and even endangering lives.
- Safety and Ethical Concerns: In sensitive applications, hallucination can pose safety and ethical risks. For example, in healthcare, incorrect medical advice or misinterpretation of symptoms could lead to harmful treatment decisions. In legal or financial domains, inaccurate information could result in costly mistakes or unfair practices.
- Damage to Brand Reputation: For companies deploying LLMs in their products or services, hallucination can lead to embarrassing and costly mistakes. Incorrect or inappropriate responses generated by these models can damage brand reputation and lead to a loss of customer trust and confidence.
- Limited Real-world Applicability: Despite their impressive capabilities, LLMs with high hallucination rates are limited in their real-world applicability. This is particularly true in enterprise settings where accuracy and reliability are non-negotiable.
Strategies to Reduce LLM Hallucination
To mitigate the drawbacks of LLM hallucination, several strategies have been proposed and explored. These include:
- Retrieval-Augmented Generation (RAG): RAG is a promising approach that combines the strengths of LLMs with the factual knowledge from external sources. By retrieving relevant information from a knowledge base or corpus and incorporating it into the generation process, RAG can help reduce hallucination and improve the factual accuracy of the generated text.
- Fine-tuning: Fine-tuning LLMs on more specific and domain-specific datasets can help improve their factual accuracy and contextuality. By refining the models’ training with targeted data, the risk of hallucination can be reduced.
- Decoding strategies: Modifying the decoding algorithms used by LLMs can also help mitigate hallucination. Techniques such as top-p truncation and diverse beam search can introduce more diversity and reduce the likelihood of generating hallucinated content.
- Architectural modifications: Some researchers have proposed changes to the underlying architecture of LLMs to address hallucination. For example, incorporating memory modules or reasoning components can help LLMs better handle algorithmic tasks and reduce hallucination.
- Prompt engineering: Carefully crafting the input prompts provided to LLMs can influence the quality and factual accuracy of the generated text. By including relevant context, instructions, and constraints, prompt engineering can help guide the LLM towards more reliable outputs.
- Hallucination detection: Developing methods to automatically detect hallucinated content can help users identify and discard unreliable outputs. This can involve techniques such as anomaly detection, consistency checking, or using separate models trained to identify hallucinations.
Among these strategies, Retrieval-Augmented Generation (RAG) stands out as an innovative approach to reduce hallucinations effectively.
RAG: A Promising Solution to LLM Hallucination
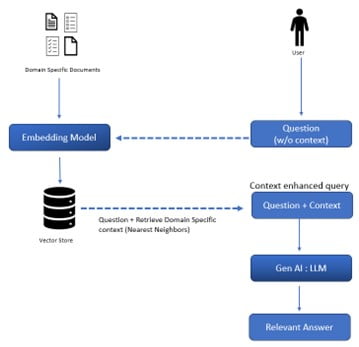
RAG can help reduce LLM hallucination in several ways. First, by retrieving relevant documents before generating a response, RAG ensures that the model has access to accurate and up-to-date information. This can help reduce the likelihood of the model generating factually incorrect or outdated information. Second, RAG can help ensure that the model’s responses are faithful to the input prompt. By using the input prompt to retrieve relevant documents, RAG ensures that the model’s responses are grounded in the user’s question or request. This can help reduce the likelihood of the model generating responses that are unrelated or only loosely related to the input. Finally, RAG can help improve the transparency and interpretability of LLMs. By providing users with a list of the documents that were retrieved and used to generate the response through the reranking approach, RAG allows users to see how the model arrived at its answer. This can help build user trust in the system and reduce the likelihood of users rejecting or distrusting the model’s responses.
RAG Pipeline:
RAG combines the generative capabilities of LLMs with the precision of information retrieval systems. By integrating real-time information retrieval into the generation process, RAG can ground the model’s responses in up-to-date and relevant data, significantly reducing the likelihood of hallucinations.
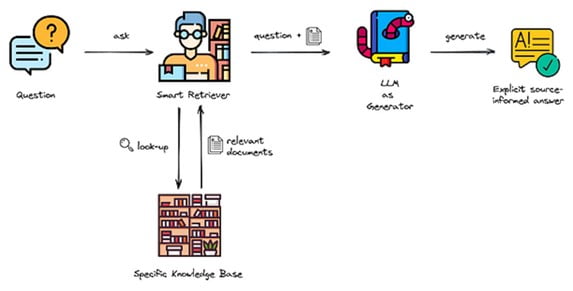
The RAG pipeline typically consists of three main components:
- Retrieval: First, given an input query or prompt, relevant information is retrieved from an external knowledge source (e.g., documents, databases, or search engines). This step aims to gather accurate and relevant information to support the model’s response.
- Encoding: The retrieved information is then encoded into a suitable format for the language model to process. This may involve using techniques like vector embeddings or sentence-level representations.
- Generation: The encoded information is fed into the LLM, guiding its generation process and enhancing factual correctness. The model is trained to generate outputs that are coherent and aligned with the provided information.
RAG Use Cases
RAG is a boost to language models in retrieving the relevant and highly contextual data and many organizations today are embracing this approach to build their chatbots and other AI applications.
Here are some use cases where RAG can be beneficial:
- Question Answering (QA): RAG can be used to enhance the performance of QA systems. The model can first retrieve relevant documents or passages from a large corpus and then generate an answer based on the retrieved information.
- Dialogue Systems: In conversational AI, RAG can help to create more contextually accurate and informative responses. The model can retrieve relevant information from past conversations or external knowledge sources and use it to generate a response.
- Summarization: RAG can be used for extractive and abstractive summarization. The model can first retrieve the most important sentences or facts from a document and then generate a concise and coherent summary.
- Machine Translation: In machine translation, RAG can help to improve the accuracy and fluency of translations. The model can retrieve relevant translation examples or bilingual dictionaries and use them to generate a translation.
- Content Creation: RAG can be used to assist in content creation, such as writing articles, blogs, or social media posts. The model can retrieve relevant information from the internet and use it to generate a draft, which can then be edited and refined by a human writer.
- Tutoring and Education: RAG models can be used to create personalized learning experiences. They can retrieve information based on a student’s learning level and past performance, and generate questions, explanations, or feedback.
These are just some prominent common example use cases but RAG is advancing at speed and there are many research projects happening around this approach.
Addressing hallucinations in Large Language Models (LLMs) is critical for enhancing the reliability and applicability of AI systems across various domains. Retrieval-Augmented Generation (RAG) emerges as a particularly promising strategy by integrating external knowledge into the generation process, thereby grounding outputs in factual and relevant data. This approach not only mitigates the risk of generating inaccurate or nonsensical information but also enhances the transparency and interpretability of model responses. By leveraging the strengths of both retrieval systems and generative models, RAG offers a robust solution to the persistent issue of hallucinations, paving the way for more trustworthy and effective AI applications in fields such as healthcare, finance, education, and beyond.
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


