
Contextual retrieval is an emerging concept in artificial intelligence that enhances the way AI systems interact with vast knowledge bases. As AI applications become increasingly complex, the need for effective information retrieval methods has grown. Traditional approaches often struggle with context loss, leading to inaccurate or incomplete responses. Contextual retrieval aims to address these challenges by providing a more nuanced understanding of the data being processed. This article explores contextual retrieval, its integration with Retrieval-Augmented Generation (RAG), and its implications for improving AI performance.
What is RAG?
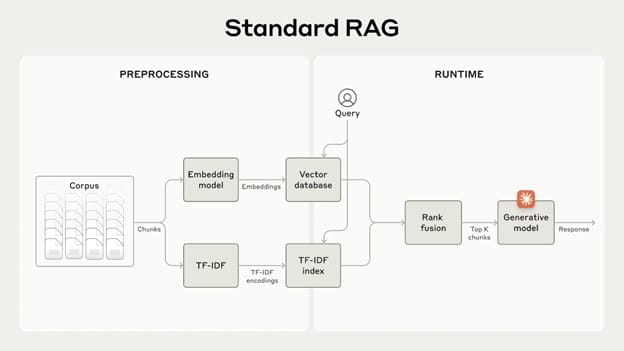
Image credits: Anthropic
Retrieval-Augmented Generation (RAG) is a technique designed to improve the performance of AI applications by integrating external knowledge into the generative process. It works by retrieving relevant information from a knowledge base and appending it to user prompts, thereby enhancing the model’s ability to generate accurate and contextually relevant responses. RAG combines two primary components: a retriever that fetches pertinent information and a generator that formulates responses based on this information. This method significantly boosts the quality of outputs in applications such as chatbots, search engines, and content generation tools. However, traditional RAG methods often strip away crucial context when encoding data, leading to potential misunderstandings or misinterpretations of the retrieved information. Recent advancements have sought to overcome these limitations through improved techniques like contextual retrieval.
Introduction to Contextual Retrieval
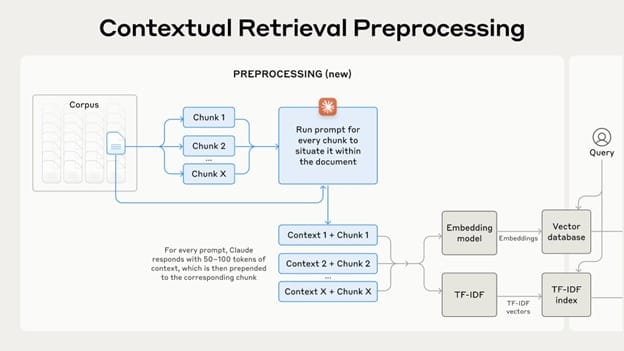
Image credits: Anthropic
Contextual retrieval is a refined approach that enhances traditional RAG systems by ensuring that the information retrieved retains its contextual integrity. This method involves adding specific contextual information to text chunks before they are embedded or indexed, preserving their relationship with broader documents. By doing so, contextual retrieval addresses a common issue where individual text chunks lose essential context, which can result in inaccurate or incomplete responses from AI models. For instance, if an AI system retrieves a chunk stating “The company’s revenue grew by 3%,” without additional context, it may be unclear which company is being referenced or during what time period this growth occurred. Contextual retrieval improves the accuracy of AI systems by ensuring that even smaller chunks of information maintain relevance and clarity.
How Contextual Retrieval Differs from Traditional RAG
Traditional RAG systems often face limitations when handling complex queries due to their reliance on basic document chunking and retrieval methods. These systems typically:
- Struggle with ambiguous or short queries
- Miss context during document splitting
- Lose important information in lengthy documents
- Require multiple retrievals for complex conversations
In contrast, contextual retrieval enhances the RAG framework by:
- Maintaining coherence throughout multi-turn conversations
- Dynamically updating context during interactions
- Processing extensive documents without performance degradation
- Understanding semantic relationships between query components
Benefits of contextual retrieval
Contextual retrieval offers significant advantages that address common search challenges and improve overall system performance:
- Enhanced Accuracy: The system can disambiguate queries by understanding context, ensuring more precise results even for ambiguous terms like “Java” (programming vs. island).
- Improved Personalization: Search results are tailored based on user preferences, search history, and contextual factors, creating a more personalized experience.
- Reduced Search Friction: Users can obtain relevant results more quickly without needing to input detailed queries, streamlining the search process.
- Better User Experience: By understanding context deeply, the system delivers more satisfying results, leading to higher engagement and user satisfaction.
The implementation of contextual retrieval also allows for the development of shared contextual knowledge bases, enabling systems to learn from multiple users while respecting privacy concerns. This collaborative approach enhances the overall search ecosystem while maintaining individual user preferences and needs.
How Contextual Retrieval Enhances AI and RAG Applications
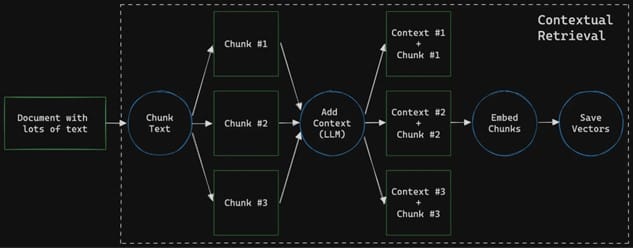
The integration of contextual retrieval into AI systems significantly enhances their performance by reducing retrieval failures and improving the overall quality of generated responses. Research shows that using contextual embeddings can decrease retrieval failure rates by up to 35%, while combining these embeddings with Contextual BM25—a modified version of the traditional BM25 algorithm—can further reduce failures by 49%. Additionally, incorporating a reranking step can lead to an impressive 67% reduction in errors during retrieval tasks.
This improvement is crucial for applications requiring high accuracy, such as customer support bots or legal document analysis. The benefits of contextual retrieval extend beyond mere accuracy; they also enhance efficiency and cost-effectiveness in processing large datasets. By minimizing context loss and optimizing the retrieval process, AI systems can deliver more reliable outputs while reducing computational costs associated with processing irrelevant or extraneous data.
Implementing Contextual Embeddings
Implementing contextual embeddings requires a systematic approach to transform traditional document processing into a context-aware system. Let’s explore the practical steps to build this enhanced retrieval mechanism.
Preprocessing documents
The foundation of effective contextual retrieval lies in proper document preprocessing. Unlike traditional approaches that simply split documents into fixed-size chunks, contextual preprocessing requires a more nuanced strategy. The process begins with intelligent document segmentation that preserves semantic coherence.
Here are the essential preprocessing steps:
- Document Analysis: Examine document structure and content type
- Semantic Segmentation: Split content while maintaining topical relevance
- Boundary Optimization: Adjust chunk boundaries to preserve context
- Metadata Extraction: Capture document hierarchy and relationships
- Quality Validation: Ensure chunks maintain semantic completeness
Generating context for chunks
Context generation transforms basic document chunks into rich, contextually-aware segments. This process leverages transformer models to understand the relationship between individual chunks and their surrounding content.
The context generation phase involves using Large Language Models (LLMs) to analyze each chunk within its broader document scope. The system examines 50-100 tokens of surrounding content to create a comprehensive contextual understanding. This additional context helps situate each chunk within the document’s narrative flow and topical structure.
Creating contextualized embeddings
The final phase involves generating embeddings that capture both the chunk content and its contextual information. Modern transformer architectures like BERT excel at this task by producing dynamic representations that reflect the contextual nature of language.
Key considerations for embedding generation:
- Select appropriate embedding models based on your use case
- Balance embedding dimension with computational resources
- Implement proper token handling for out-of-vocabulary words
- Optimize batch processing for large-scale implementations
- Monitor embedding quality through similarity metrics
The embedding process uses bidirectional context analysis to create vectors that represent not just the words, but their meaning within the specific document context. These contextualized embeddings adapt dynamically based on surrounding content, unlike traditional static embeddings that assign fixed vectors to words.
For optimal implementation, maintain a token budget of 256-512 tokens per chunk, allowing sufficient context while keeping computational requirements manageable. The resulting embeddings should capture both local semantic information and broader document context, enabling more accurate retrieval during search operations.
Remember to implement proper validation mechanisms to ensure your embeddings effectively capture contextual relationships. This includes testing embedding quality through similarity searches and evaluating retrieval performance on diverse query types.
Enhancing Retrieval with Contextual BM25
Building effective search systems requires a sophisticated approach to keyword matching and semantic understanding. BM25 (Best Matching 25) serves as a powerful foundation for enhancing contextual retrieval systems through precise lexical matching capabilities.
Implementing BM25 for keyword matching
BM25 operates as a probabilistic ranking function that evaluates document relevance based on several key components:
- Term Frequency (TF): Measures word occurrence frequency
- Inverse Document Frequency (IDF): Weighs term importance
- Document Length Normalization: Prevents bias toward longer documents
- Query Term Saturation: Controls impact of repeated terms
The implementation follows this scoring formula:
Score(d,q) = ∑(tf(i,d) * idf(i) * (k1 + 1)) / (tf(i,d) + k1 * (1 – b + b * (dl/avgdl)))
This algorithm excels at handling technical queries, especially when dealing with specific identifiers or precise terminology. For instance, when searching for “Error code TS-999,” BM25 efficiently locates exact matches while embedding models might only find general content about error codes.
Combining with contextual embeddings
The power of contextual retrieval emerges when BM25 joins forces with contextual embeddings. This hybrid approach creates a robust search system that leverages both exact matching and semantic understanding. The integration process involves:
- Creating TF-IDF encodings for document chunks
- Generating contextual embeddings for semantic matching
- Implementing rank fusion techniques
- Combining results using weighted scoring
The system normalizes and weights scores from both methods:
combined_scores = 0.5 * bm25_scores_normalized + 0.5 * dense_scores_normalized
Optimizing retrieval accuracy
Our experiments demonstrate significant improvements in retrieval performance through contextual BM25 implementation:
- 35% reduction in top-20-chunk retrieval failure rate using Contextual Embeddings
- 49% reduction when combining Contextual Embeddings with Contextual BM25
To optimize your implementation, consider these critical factors:
- Chunk Management: Carefully select chunk sizes and overlap parameters
- Model Selection: Choose appropriate embedding models for your domain
- Context Window: Balance between information completeness and processing efficiency
- Custom Prompts: Develop domain-specific contextualizer prompts
- Performance Monitoring: Implement continuous evaluation metrics
The system’s effectiveness stems from its ability to handle both precise technical queries and broader conceptual searches. For technical documentation, BM25 excels at finding specific error codes or version numbers, while contextual embeddings capture related concepts and solutions. This dual approach ensures comprehensive coverage of user information needs.
Remember to maintain proper document length normalization and term saturation controls to prevent common words from dominating the results. The hybrid system should dynamically adjust weights based on query characteristics and document collections to achieve optimal performance.
Evaluating and Optimizing Performance
Effective evaluation of search system performance is crucial for ensuring optimal user experience and system reliability. Understanding how well your contextual retrieval system performs requires a comprehensive approach to measurement and optimization.
Measuring retrieval accuracy
The success of a contextual retrieval system depends on several key performance indicators. Here are the essential metrics for evaluation:
1. Precision and Recall
- Precision measures the accuracy of retrieved results
- Recall indicates the completeness of relevant document retrieval
- F1 Score combines both for balanced evaluation
2. Mean Average Precision (MAP)
- Evaluates ranking quality across multiple queries
- Considers both precision and position in results
- Provides comprehensive performance assessment
3. Normalized Discounted Cumulative Gain (NDCG)
- Measures ranking quality with graded relevance
- Accounts for position-based result importance
- Enables cross-system comparison
A/B testing contextual vs. traditional approaches
When comparing contextual retrieval systems with traditional approaches, structured A/B testing provides valuable insights. Our experiments revealed significant improvements:

The testing process should focus on:
- User interaction patterns
- Response relevance
- Query completion time
- System adaptation capability
Fine-tuning the system for your use case
Optimizing contextual retrieval systems requires careful attention to several key parameters. The process involves iterative refinement based on performance metrics and user feedback.
Chunk Optimization fine-tuning begins with chunk management. Consider implementing these strategies:
- Adjust chunk size based on document type (50-100 tokens optimal)
- Maintain consistent overlap between chunks
- Balance context window size with processing efficiency
Model Selection and Configuration different embedding models show varying performance levels. Our research indicates:
- Gemini embeddings excel in technical documentation
- Voyage embeddings perform well for general content
- Custom domain-specific models may provide better results
Performance Monitoring implement continuous monitoring through:
- Real-time performance tracking
- User feedback analysis
- System response time measurement
- Error rate monitoring
For optimal results, consider these fine-tuning recommendations:
1. Start with baseline measurements
2. Implement incremental changes
3. Monitor impact on key metrics
4. Adjust based on performance data
5. Validate improvements through A/B testing
The evaluation process should be ongoing, with regular assessment of system performance against established benchmarks. This iterative approach ensures continuous improvement while maintaining system stability and reliability.
Example Use Case: Implementing Contextual Retrieval
To illustrate how contextual retrieval can be applied in practice, consider a simple use case involving a customer support chatbot designed to assist users with product inquiries. The implementation steps might include:
- Document Chunking: Break down product manuals or FAQs into smaller text chunks.
- Contextual Annotation: Use an AI model like Anthropic’s Claude to generate concise contextual explanations for each chunk.
- Embedding Creation: Convert these annotated chunks into embeddings suitable for indexing.
- Indexing with BM25: Create an index using both traditional BM25 and contextual BM25 methods to facilitate efficient searching.
- Query Processing: When a user asks a question (e.g., “How do I reset my device?”), the system retrieves relevant chunks based on both semantic similarity and exact matches.
- Response Generation: Finally, the retrieved context is used as input for a language model to generate a coherent response.
Here’s a simplified code snippet demonstrating how one might set up such a system using Python:
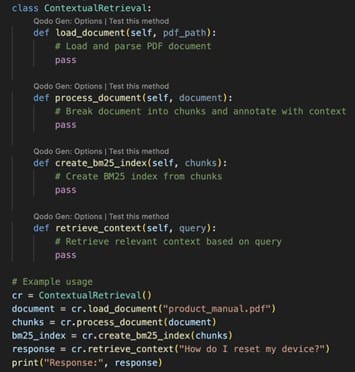
This example outlines how developers can leverage contextual retrieval techniques to build more effective AI applications capable of understanding and responding accurately to user inquiries.
Conclusion
Contextual retrieval represents a significant advancement in the field of artificial intelligence, particularly in enhancing the capabilities of RAG systems. By ensuring that retrieved information retains its context, this approach not only improves accuracy but also optimizes efficiency in processing large datasets. As AI continues to evolve, integrating techniques like contextual retrieval will be essential for developing more sophisticated and reliable applications across various domains. With tools like Anthropic’s Claude facilitating these advancements, businesses can harness the power of improved information retrieval to create more intelligent and responsive AI systems capable of meeting complex user needs effectively.
References
- Anthropic’s Contextual Retrieval Announcement
- Anthropic’s Breakthrough in Contextual Retrieval
- RAG and Contextual Retrieval Explained
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


