
Large language models (LLMs) are trained on vast text data to understand, generate, and manipulate human language using deep learning neural networks like transformers. LLMOps (Large Language Model Operations) has emerged as a specialized field focused on managing the entire LLM lifecycle, from data management and model development to deployment and monitoring.
Companies are paving the way in LLMOps, providing tools and practices to ensure the efficient, reliable, and ethical operation of LLM-powered applications. LLMOps workflows involve preprocessing data, model selection, responsible AI evaluation, response generation, and post-processing, addressing challenges like latency, security, and transparency. As LLMOps evolve, they promise advancements in prompt engineering, model monitoring, and infrastructure optimization for large language models.
What is LLMOps
LLMOps: Managing the Lifecycle of Large Language Models
LLMOps (Large Language Model Operations) encompasses the practices, techniques, and tools used for the operational management of large language models in production environments. It is a specialized discipline within the broader field of MLOps (Machine Learning Operations), focused on addressing the unique challenges posed by the scale and complexity of large language models.
LLMOps differs from traditional MLOps in several ways, including:
- Computational Resources: LLMs require significant computational resources for training, fine-tuning, and inference.
- Transfer Learning: LLMOps often involves transfer learning techniques, such as prompt engineering, fine-tuning, and Retrieval Augmented Generation (RAG), rather than training foundation models from scratch.
- Human Feedback: LLMOps incorporates human feedback loops for model evaluation, monitoring, and iterative improvement.
- Hyperparameter Tuning: LLMs have a large number of hyperparameters that need to be tuned for optimal performance.
- Performance Metrics: LLMOps requires specialized metrics for evaluating language model performance, such as perplexity, BLEU, and ROUGE.
- Prompt Engineering: LLMOps involves the development and management of prompts, which are crucial for effective utilization of LLMs.
- LLM Chains and Pipelines: LLMOps often involves building complex chains or pipelines of LLMs to achieve specific tasks.
A complete comparison chart is below for your reference.
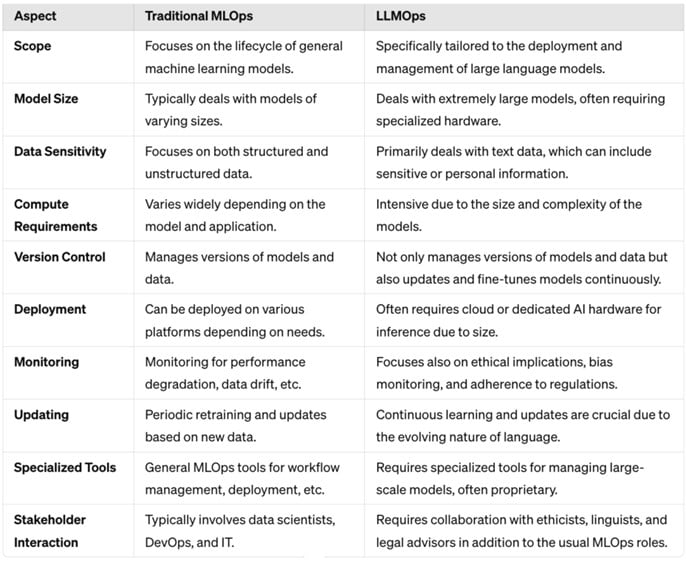
Key Components of LLMOps
Here is a comprehensive overview of the key components of LLMOps. It’s essential to break down the process into these distinct areas to ensure the successful deployment and management of large language models. Let’s dive deeper into each component:
- Model Training and Fine-Tuning: This is the foundation of LLMOps. By leveraging vast datasets, you can teach the model to generate accurate and contextually appropriate responses. This step is crucial for developing a model that can effectively understand and respond to user input.
- Infrastructure Management: As you mentioned, robust computational resources and efficient data handling capabilities are vital for supporting the considerable processing needs of large models. This includes ensuring the scalability of infrastructure to accommodate growing demands and handling large datasets.
- Monitoring and Maintenance: Regular monitoring and maintenance are essential for ensuring model reliability and performance. This involves continuous assessment of output quality, identifying and addressing any emerging issues or biases, and updating the model to maintain its effectiveness.
- Ethical Governance: As you emphasized, ethical governance is a critical component of LLMOps. It’s essential to ensure the responsible use of language models in compliance with privacy laws and ethical standards. This includes implementing measures to prevent biases, protecting user data, and promoting transparency.
- User Interface Design: A well-designed user interface is crucial for effective interaction with the model. A user-friendly interface can significantly impact how users utilize the model’s capabilities in various applications.
An LLMOps platform provides a collaborative environment for data scientists and engineers to manage the entire LLM development lifecycle, from data exploration to model deployment and monitoring.
LLMOps Workflow
Exploration Phase
- Ideation and Feasibility Assessment: Brainstorm ideas, assess implementation complexity, and gather sample data to understand LLM capabilities.
- Data Sourcing and Curation: Identify data sources, curate a high-quality dataset, and define key metrics for evaluating model performance.
Experimentation and Adaptation
1. Model Selection and Customization: Explore techniques to adapt and customize the model to better suit the use case, such as in-context learning, retrieval augmented generation, and fine-tuning.
2. Prompt Engineering: Use best practices with reusable prompt templates, versioning, prompt catalogs, and evaluation with golden sets. This involves:
- Tokenization: Segmenting the prompt into smaller units called tokens.
- Data Normalization: Removing/transforming noisy data, correcting typos, standardizing text.
- Encoding: Converting tokens into numerical form using embeddings.
- Grounding: Contextualizing the prompt based on previous conversation or external knowledge.
- Entity Recognition and Linking: Associating entities with relevant context.
- Prompt Evaluation: Evaluating prompts against safety and compliance guidelines.
Deployment and Monitoring
System Integration: Integrate the LLM interface into the application stack, implement workflow patterns, and expose interfaces to enterprise and external systems. This may involve:
- Decoding: Converting numerical model output back into human-readable text.
- Response Refinement: Improving grammar, style, and readability of the response.
- Caching: Storing frequently used or computationally intensive model outputs.
- Concurrent Processing: Optimizing resource utilization by processing multiple requests concurrently.
- Performance Monitoring: Identifying and addressing performance bottlenecks.
- Model Optimization: Using pre-fine-tuned models or long-context variants, customizing models through fine-tuning on relevant datasets.
- Data Formatting: Maintaining consistent data formatting (e.g. JSON Lines) for training and inference.
- Advanced Techniques: Few-shot prompting, chain-of-thought reasoning, and prompt templates.
- Deployment Workflows: Real-time API-based deployment or batch processing workflows.
- Model Packaging and Versioning: Consistent deployments through model packaging and versioning.
- CI/CD Pipelines: Automated testing and deployment via CI/CD pipelines.
- Orchestration: Managing the order of LLMOps workflow steps.
- Infrastructure: Leveraging high-performance hardware (GPUs, TPUs), load balancing, geographical distribution, and ensuring data privacy and security.
Launch and Iterate: Ship the LLM application, monitor system metrics and model performance, and implement continuous integration and delivery pipelines. This involves:
- Model Deployment: Integrating the trained model into an application, setting it up to respond to API calls, or making it available for end-users.
- Inference: Providing the deployed model with input (prompts) and receiving output (predictions) based on the learned patterns.
- Monitoring and Management: Continuously monitoring and managing the deployed LLM to ensure it operates within ethical guidelines, checking for biases, fairness, and the overall societal impact of the model’s predictions.
The LLMOps workflow encompasses key stages like exploration, experimentation, adaptation, deployment, monitoring, and iterative improvement, enabling organizations to effectively develop, deploy, and maintain LLM-powered applications in production environments.
Choosing the Right LLM
Understand Your Requirements
Before selecting an LLM, it’s crucial to understand the specific objectives you want to achieve, such as improving automation, creating content, summarizing, analyzing or translating text, implementing a chatbot, or generating code. Thoroughly analyze your use case requirements against the capabilities and limitations of available LLM options.
Evaluate Cost and Licensing
Some LLMs are open-source and freely available, while others require licenses or have usage fees. Determine if the model is open-source or requires licenses/usage costs, ensuring it fits within your budget and resource constraints. Choose between proprietary or open-source foundation models based on factors like performance, cost, ease of use, and flexibility.
Consider Model Size and Latency
1. Model Size: Larger models with more parameters generally have better performance, but there is a tradeoff with increased latency. Smaller models may be faster but less capable.
2. Latency: If your use case requires real-time responses, consider the model’s latency. Assess the model’s accuracy, precision, recall, and response time/latency, considering the requirements of your real-time or low-latency applications.
Fine-tuning Capabilities
Ensure the LLM supports fine-tuning, which allows you to retrain the model on your specific data and tasks. Evaluate if the model supports fine-tuning on your specific domain or task-specific dataset, as customization is important if you need to adapt the model to your use case.
Hallucination and Bias
Investigate the model’s propensity for hallucination (generating inaccurate or nonsensical responses) and potential biases, as well as the transparency of the training process. Evaluate the model’s development practices and guidelines for addressing bias and generating appropriate content, considering ethical and responsible AI considerations.
Available LLM Options
Some examples of available large language models to evaluate include:
- Llama 2 (open-source)
- Llama 3 (open-source)
- Mistral 7B (open-source)
- Falcon (open-source)
- PaLM 2 (open-source)
- GPT models (proprietary)
- Claude (proprietary)
Testing and Benchmarking
Test and benchmark models with your own data to make the right choice. Focus on finding the optimal balance of accuracy, speed, scalability, and ethical alignment for your needs. Avoid getting swayed by hype alone and choose the LLM that best fits your requirements.
LLM Components and Considerations
The main components of an LLM include training data, input representation, pre-training objective, and model architecture. For real-world use, LLMs typically require fine-tuning on domain-specific data for downstream tasks, but some models like GPT-3 support few-shot or zero-shot learning. When selecting an LLM, consider:
- Alignment between the pre-training objective and downstream task
- Benchmarking results
- Testing on real-world data
- Tradeoffs between fine-tuning and few-/zero-shot learning
LLMs have limitations in terms of up-to-date knowledge and reasoning capacity, so they may need to be combined with other knowledge sources for certain applications. By carefully evaluating your requirements, model capabilities, and potential limitations, you can make an informed decision and choose the LLM that best suits your specific use case.
Preparing the LLM for Deployment
Infrastructure Requirements
Deploying large language models (LLMs) in production environments requires significant computational resources and infrastructure considerations. Here are some key aspects to prepare for:
- Hardware Acceleration: LLMs heavily rely on powerful GPUs or TPUs for efficient training and inference. Ensure you have access to high-performance hardware accelerators, either on-premises or through cloud providers.
- Cloud or On-Premises Deployment: LLMs can be deployed in the cloud (e.g., AWS, Azure, GCP) or on-premises infrastructure. Cloud deployments offer scalability and managed services, while on-premises setups provide more control and data privacy.
- Storage Capacity: LLMs require large storage capacities to store model weights, training data, and results. Ensure you have sufficient storage resources, potentially leveraging distributed file systems or object storage solutions.
- Frameworks and Libraries: Popular deep learning frameworks like TensorFlow, PyTorch, and Hugging Face Transformers are commonly used for building and deploying LLMs. Choose a suitable framework based on your team’s expertise and the model’s requirements.
Data and Model Preparation
- Pre-trained Models: Access pre-trained LLM parameters or fine-tune the model on your specific data and tasks. Fine-tuning can significantly improve performance for specific use cases.
- Data Preprocessing: Prepare your data by cleaning, formatting, and tokenizing it for compatibility with the chosen LLM framework.
- Model Containerization: Package the LLM and its dependencies into Docker containers for consistent and isolated deployments across different environments.
Security and Governance
- Data Security: Implement robust security measures to protect sensitive data used for training or inference. This may involve secure gateways, private cloud instances, or on-premises deployments.
- Employee Training: Provide comprehensive training to employees on data security protocols and best practices when using LLMs, especially for public models like ChatGPT.
- Enterprise-friendly Options: Explore enterprise-friendly LLM solutions like Microsoft Copilot, which offer ease of use with additional controls and security features.
- Responsible AI Evaluation: Evaluate the LLM for potential biases, hallucinations, and adherence to responsible AI principles before deployment.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is an approach that separates proprietary data from the LLM, making it easier to swap models or use open-source options. With RAG, vector databases like ChromaDB and Pgvector are used to enable accurate and relevant information retrieval, which is then embedded into LLM prompts.
Companies like Salesloft, Ikigai Labs, and PwC leverage RAG with open-source LLMs and vector databases, as it offers more flexibility and efficiency compared to fine-tuning for most enterprise deployments. However, fine-tuning can still be useful for specific use cases like customer service.
By carefully preparing the infrastructure, data, and model, implementing security measures, and exploring techniques like RAG, organizations can effectively deploy LLMs in production environments while mitigating risks and ensuring responsible AI practices.
Deployment and Monitoring
Deployment Options
- Cloud Storage: Cloud storage services like Amazon S3 and Google Cloud Storage can be leveraged to store the large trained LLM models.
- Cloud Platforms:
- Google Cloud AI Platform: This platform can be used to deploy the LLM model, but there are size limitations that may require adjusting the model size or contacting Google to increase the quota.
- Amazon SageMaker: Amazon SageMaker is a service that can handle deploying even large transformer models.
- Caching and Optimization: When loading the LLM model in a web app, caching and other optimization techniques should be employed to avoid repeated loading and minimize bandwidth consumption.
Serving the LLM
- User Interface: Set up an interface for users to interact with the LLM model, such as a web app, chatbot, or command-line tool.
- API Integration: Integrate with APIs for pre-trained LLMs like GPT-3 to leverage their capabilities.
- Input/Output Handling:
- Implement user input handling to preprocess and format data for the LLM.
- Post-process the LLM’s outputs to enhance readability, grammar, and style.
- Considerations:
- Scalability: Ensure the deployment can handle increasing user traffic and demand.
- Performance: Optimize the LLM’s performance for low-latency responses.
- User Experience: Design a seamless and intuitive user experience for interacting with the LLM.
- Security and Privacy: Implement robust security measures and adhere to data privacy regulations.
Monitoring and Maintenance
- Testing: Thoroughly test the LLM deployment to identify and resolve any issues or bugs.
- Optimization: Continuously optimize the LLM’s performance, efficiency, and resource utilization.
- Monitoring: Monitor the LLM’s performance, outputs, and adherence to responsible AI principles.
- Maintenance: Regularly maintain and update the LLM deployment to ensure optimal operation and incorporate improvements.
By following these guidelines, organizations can effectively deploy and serve LLMs in production environments, ensuring scalability, performance, security, and responsible AI practices. Continuous monitoring and maintenance are crucial for maintaining the LLM’s reliability and effectiveness over time.
Iterative Improvement
Continuous Improvement and Adaptation
Deploying large language models (LLMs) is just the beginning; iterative improvement and adaptation are crucial for ensuring their long-term success and reliability. This process involves continuous monitoring, evaluation, and refinement of the LLM’s performance, outputs, and decision-making capabilities.
- Feedback Loops: Establish feedback loops to gather real-time insights from users, subject matter experts, and other stakeholders. This feedback can be used to identify areas for improvement, such as biases, inaccuracies, or performance issues.
- A/B Testing: Conduct A/B testing in production environments to compare the performance of different LLM configurations, prompts, or fine-tuning techniques. This data-driven approach can help identify the most effective strategies for your specific use case.
- Active Learning and Adaptive Models: Leverage active learning techniques to continuously refine and update the LLM’s knowledge base. Adaptive models can dynamically adjust their behavior based on new data and feedback, enabling them to adapt to evolving requirements and scenarios.
Quantitative and Qualitative Evaluation
Evaluating the performance and outputs of LLMs requires a combination of quantitative metrics and qualitative analysis methods.
- Quantitative Metrics: Utilize established metrics like BLEU score, ROUGE score, and METEOR score to assess the quality of LLM outputs, such as text generation or translation tasks. These metrics provide objective measures of performance and enable benchmarking against industry standards.
- Qualitative Analysis: Implement comprehensive evaluation strategies that involve human evaluation and user experience analysis. This can include manual review of LLM outputs, user feedback surveys, and usability testing to assess the real-world impact and effectiveness of the LLM.
Model Fine-Tuning and Optimization
Iterative improvement often involves fine-tuning the LLM on task-specific data and optimizing its performance. This process includes the following steps:
- Data Preparation: Curate and preprocess relevant data for fine-tuning, ensuring it aligns with the target task or domain.
- Fine-Tuning Techniques: Explore different fine-tuning techniques, such as prompt-based fine-tuning, intermediate task transfer, or domain-adaptive pretraining, to enhance the LLM’s performance on specific tasks.
- Hyperparameter Optimization: Systematically tune the LLM’s hyperparameters, such as learning rate, batch size, and regularization techniques, to optimize its performance and generalization capabilities.
- Training and Monitoring: Implement robust training and monitoring processes, including early stopping, checkpointing, and performance tracking, to ensure efficient and effective fine-tuning.
- Re-evaluation: After fine-tuning, re-evaluate the LLM’s performance using the established quantitative metrics, qualitative analysis methods, and key performance indicators (KPIs) specific to your use case.
Iterative Improvement Methodology
The iterative improvement process is a methodology designed to systematically enhance the uniformity and accuracy of confidence levels attributed to individual sub-statements in the LLM’s training data. This process involves the following steps:
- Initial Confidence Assessment: LLMs assign initial confidence levels to sub-statements based on their learned likelihood or validity.
- Model Adjustment: The model undergoes iterative adjustments to refine the confidence levels of sub-statements and compound statements, with ‘ground-truths’ informing the weight adjustments.
This iterative improvement process offers several transformative advantages, including enhanced reliability, improved transparency, increased robustness, and continuous learning capabilities for LLMs.
By leveraging built-in feedback functions, programmatically evaluating inputs, outputs, and intermediate results, and iterating on prompts, hyperparameters, and other aspects based on observed weaknesses, organizations can continuously improve the performance and reliability of their LLM applications.
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


