
Introduction
In a world awash with data, the sheer volume can be overwhelming. By 2025, experts project that global data will surge to an astounding 175 zettabytes, signifying the colossal digital footprint of our age. Yet, amidst this data deluge, many organizations grapple with an existential challenge: how to transform this data into a strategic asset?
Unreliable data sources, outdated information, and engineering bottlenecks plague data professionals, with 90% facing hurdles in their daily work. The solution lies in embracing a modern data platform. It’s not just another technical upgrade; rather, it embodies a holistic approach. By integrating data ownership, storage, and smart technology, these platforms light the path toward data enlightenment.
Our Solution
Our modern data platform solution empowers organizations with open-source tools, a future-proof architecture, and scalable components to enhance agility, minimize costs, and unlock the full potential of data.
Seamless Data Integration
At the heart of this solution is Airbyte, an open-source tool that simplifies data ingestion. With prebuilt connectors and the ability to create custom connectors, Airbyte enables users to seamlessly gather data from a wide range of sources. This ensures that data flows effortlessly into a centralized data store – a data lake or a data warehouse.
Powerful Data Transformations
To empower users in shaping and preparing their data, the solution leverages DBT. This powerful tool allows both engineers and analysts to perform advanced data transformations using Python and SQL. It’s the key to turning raw data into valuable insights.
Efficient Workflow Orchestration
Airflow achieves efficiency in data processes by handling workflow orchestration. Users can define task dependencies, schedule data processes, and monitor the entire workflow with ease. This not only enhances productivity but also reduces operational complexities.
Flexible Storage Options
Our solution provides flexibility in storage options. Whether it’s Amazon S3, Redshift, or external data stores, users have the flexibility to choose the storage solution that aligns perfectly with their specific use cases and scalability requirements.
Diverse Data Distribution
Finally, the solution supports diverse data distribution. Integration with popular visualization tools like Excel, Tableau, Power BI, and Superset allows users to effortlessly share and access data-driven insights. This promotes collaborative data exploration and empowers decision-makers.
Architecture Overview
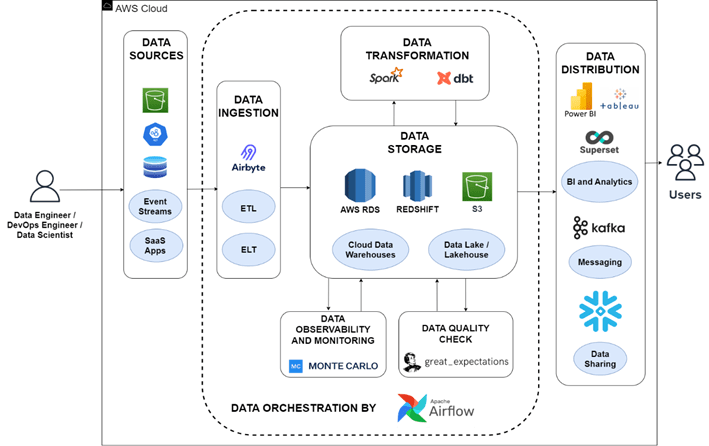
Infrastructure as Code
Terraform simplifies the management and configuration of cloud resources by using code-based templates. Terraform allows for easy changes to solution components through a few code modifications. By defining the desired state of infrastructure in declarative configuration files, which can be version-controlled and shared among teams, Terraform enables the provisioning, modification, or removal of resources such as virtual machines, networking, storage, and security groups. Modifying these files allows for creating new environments, scaling resources, or updating configurations, ensuring consistency across deployments. Terraform’s modular approach allows for reusing and composing infrastructure components, promoting code reusability and reducing duplication. By adopting Terraform, organizations can efficiently manage their infrastructure, achieve rapid provisioning, and seamlessly adapt to evolving business needs while minimizing the risk of manual errors.
Infrastructure Overview
Building the entire infrastructure for the Modern Data Platform on AWS is a two-step process, consisting of Pre-Infrastructure (Pre-Infraset) and the actual Infrastructure.
Pre-Infrastructure
The Pre-Infraset is the preliminary stage where foundational elements are set up using Terraform code, a powerful tool for building, changing, and versioning infrastructure efficiently. By running the command terraform apply from the local system, the Terraform code is executed, creating essential components such as CodePipelines for Continuous Integration and Continuous Deployment (CI/CD), S3 buckets for pipeline artifacts, and Elastic Container Registry (ECR) repositories. The user needs to initiate this process from their local system, allowing for control and customization. Pre-Infraset lays the groundwork for the main infrastructure, ensuring that the necessary components are in place for the next stage.
Infrastructure
The infrastructure stage involves creating the actual infrastructure for the Modern Data Platform, utilizing Terraform code. Building upon the foundation set by the Pre-Infraset, this stage leverages the infrastructure code-pipeline established earlier. Initiated by executing terraform apply within the code-pipeline, Terraform takes charge, executing the code and thereby creating all necessary resources for the Modern Data Platform. These resources may include EC2 instances, S3 buckets, IAM roles, and RDS or Redshift clusters. The combination of Pre-Infraset and Infrastructure stages results in a robust and fully functional infrastructure tailored for the Modern Data Platform, ready to handle the complex data processing and transformation tasks.
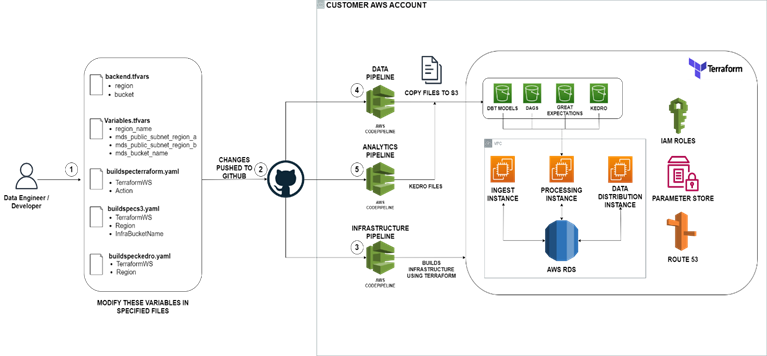
In summary, the two-component approach ensures a streamlined and efficient building process, leveraging Terraform’s capabilities to create a comprehensive infrastructure on AWS. The Pre-Infraset sets the stage, while the infrastructure component brings the Modern Data Platform to life.
Application Orchestration
The Application code is the driving force behind the Modern Data Platform, orchestrating the complex flow of data from source to destination. It’s a meticulously crafted system that leverages various tools and technologies to ensure seamless data processing, transformation, and observability.
CodePipeline and S3 Buckets
A separate code-pipeline, created during the pre-infrastructure stage, plays a pivotal role in managing the Application code. This pipeline revolves around DAG files, DBT model files, and Great Expectations suite files, all stored in S3 buckets. Whenever modifications are made to these files and the pipeline is triggered, the updated versions are automatically synchronized with the corresponding S3 buckets. Following this, the files are seamlessly mounted onto the Processing EC2 instance, which was set up during the infrastructure phase. This automated process ensures efficiency and consistency in managing and deploying the updated files across the Modern Data Platform environment.
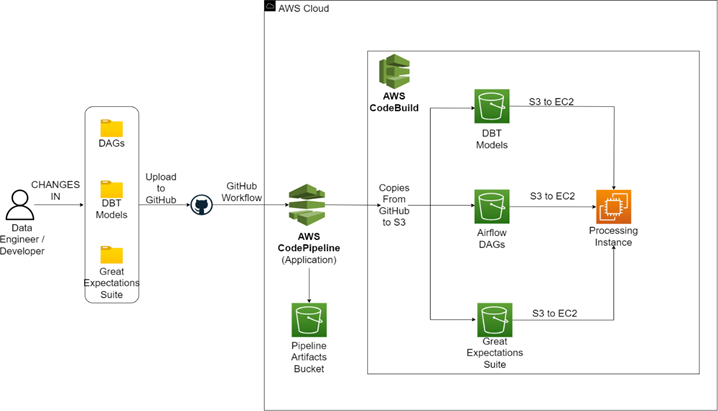
Applications
The platform hosts applications for Airbyte, Airflow, and Superset, each running on Ingest, Process, and Distribute instances respectively. These instances, created during the infrastructure stage, operate on their respective public IPs, ensuring accessibility and performance. The Process Instance is particularly robust, containing internal tools like DBT, Kedro, and Great Expectations for Data Transformations and Observability.
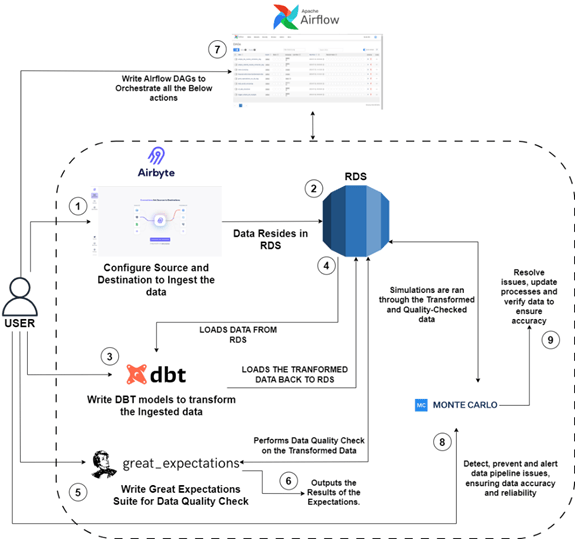
The Flow
The entire flow is a masterclass in orchestration, beginning with making a connection in Airbyte from Source to Destination. Once the connection ID is obtained, it is integrated into the DAG. This integration facilitates the creation or modification of DBT models based on the data schema. Similarly, adjustments or new creations in the Great Expectations Suite are implemented as required, ensuring alignment with the data’s characteristics. These elements are all orchestrated by the DAGs, culminating in the final delivery of data into RDS.
The User can follow this diagram for better understanding of the flow:
Components Overview
The Modern Data Platform is a symphony of interconnected components, each playing a vital role in the data lifecycle. These components are not just tools; they are the pillars that uphold the platform’s commitment to efficiency, accuracy, and innovation. Let’s delve into these core components:
Ingestion
Ingestion is the gateway to the data lifecycle, where data from various sources is collected, imported, and integrated into the system. It’s not just about pulling data; it’s about understanding the nature, format, and context of the data. The efficiency of ingestion sets the stage for all subsequent processes, determining how smoothly the data flows through the entire pipeline.
Airbyte
Airbyte takes the concept of ingestion to the next level. It’s designed to handle a wide array of data sources, ensuring seamless integration and transfer. With its adaptability and robust connectors, Airbyte makes data ingestion a streamlined experience, accommodating diverse data formats and connections, and laying a strong foundation for the entire data platform.
The concept of Connectors from various sources to destinations along with data syncs (Incremental and Full) is what makes Airbyte one of the best choices for Data Ingestion.
Below image shows the sync history happening for the connection created between AWS Data-Exchange API source (Custom source) and AWS RDS instance:
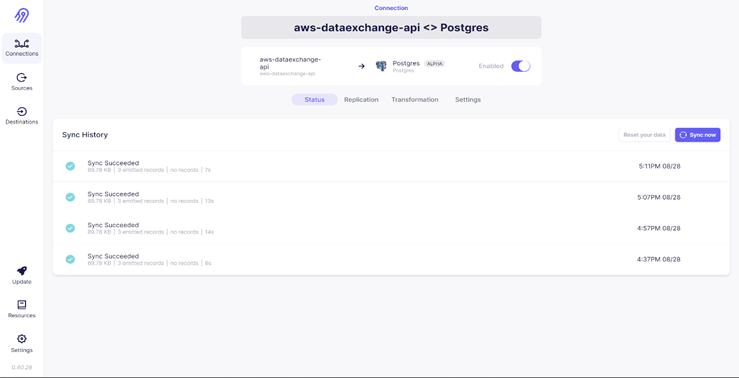
Below image shows the schema representation of the data to be ingested into the RDS destination for the same connection:
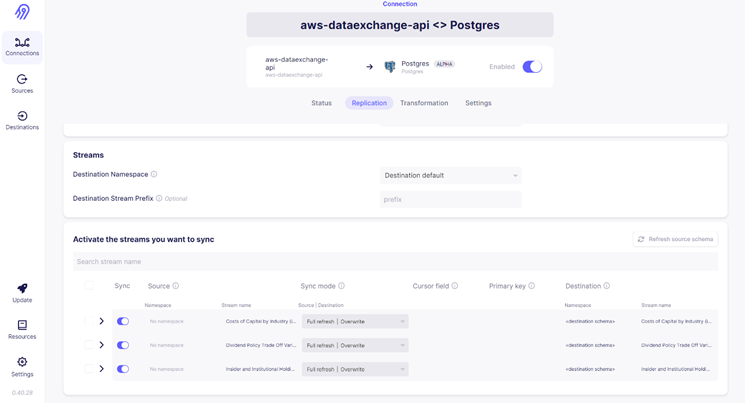
Orchestration
Orchestration is the conductor of the data symphony, coordinating and managing various tasks and workflows within the system. It ensures that every step is executed in the right sequence, at the right time, maintaining the flow and integrity of the entire process. Orchestration is about creating harmony within the system, making sure that all components work together seamlessly.
Apache Airflow
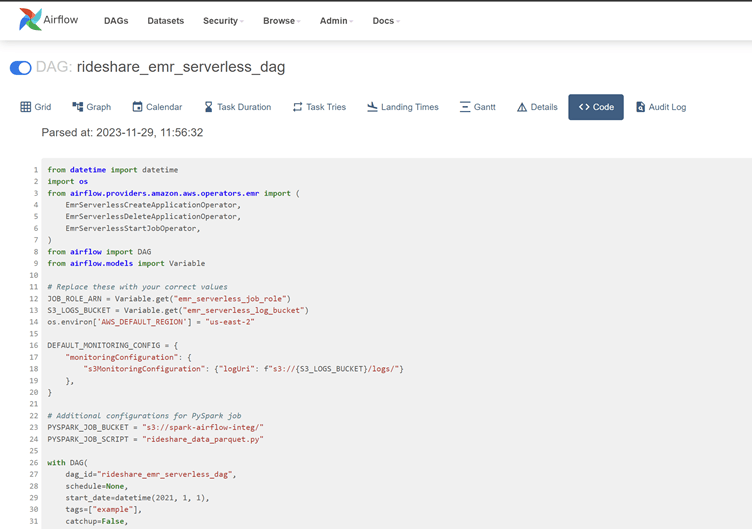
Apache Airflow serves as the orchestrator within the Modern Data Platform. Its robust scheduling, monitoring, and automation capabilities keep the data flow smooth and error-free. In the current Modern Data Platform system, Airflow’s flexibility enables the creation of complex workflows that ensure efficient execution and alignment of every task. Acting as the glue binding the entire system together, Airflow orchestrates the ingestion from Airbyte, data transformations by DBT, and data quality checks by Great Expectations seamlessly. This is achieved by writing DAGs (Directed Acyclic Graphs) using any scripting language, such as Python. DAGs can be created for various use-cases, including Post-Ingestion Transformations, Ingest-level Transformations, and others.
Below image shows the Airflow UI with DAGs:
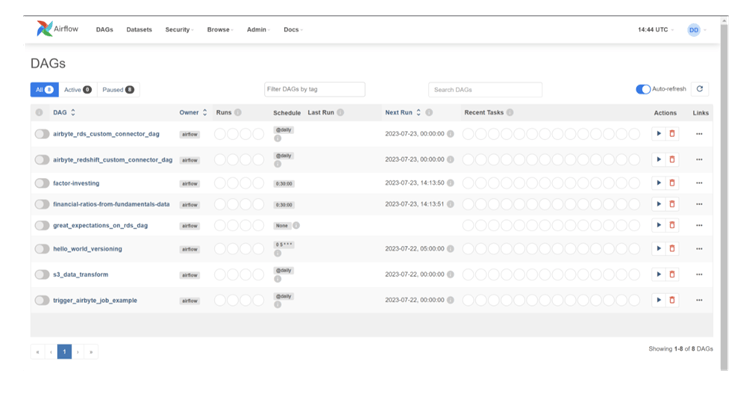
Below image shows the flow-graph of the DAG, which performs Ingestion using Airbyte and Transformation using DBT as a sequence in one-single operation:
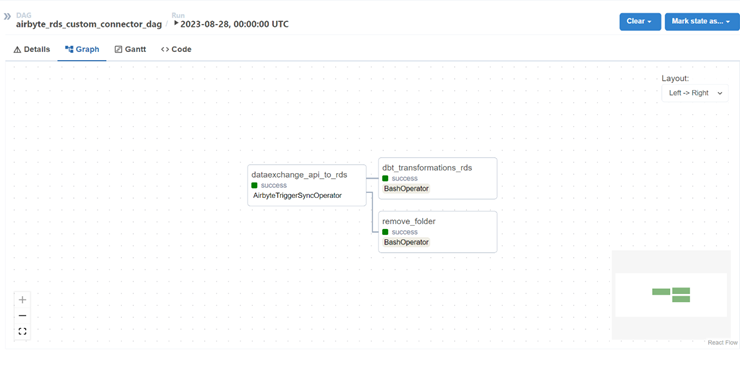
Transformations
Transformation is where raw data undergoes a metamorphosis into meaningful insights. It involves complex processes like cleaning, aggregating, enriching, and restructuring the data according to specific business logic. Transformation turns raw data into valuable information, shaping it into a form that can drive actionable insights and decisions.
DBT:
DBT (Data Build Tool) is the artisan behind data transformation within the platform. It allows analysts and engineers to define, document, and execute data transformation workflows using SQL. With its ability to enhance the value and relevance of the data, DBT plays a pivotal role in turning data into a strategic asset. In the current context of MDP on AWS, the DBT profile is configured to connect with RDS or Redshift clusters. It executes operations specified in SQL queries (DBT models), and the resulting golden-copy data is loaded into the same warehouse or database as new tables or views.
Raw data ingested from AWS Data-Exchange API using Airbyte in RDS (Data is in JSON Binary format):
New table after applying the DBT transformations:
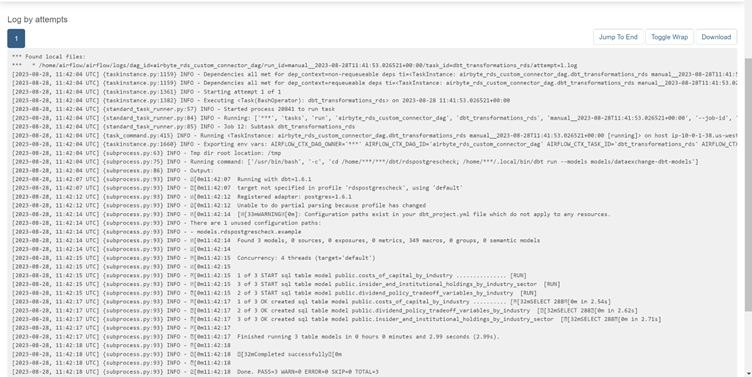
Log output of running DBT in a DAG in Airflow:
Apache Spark
Apache Spark, a powerful open-source distributed computing framework, takes centre stage in our Modern Data Platform’s data transformation strategy. Spark’s ability to process vast volumes of data in parallel, coupled with its versatility for various data processing tasks, makes it a key player in our dynamic data ecosystem.
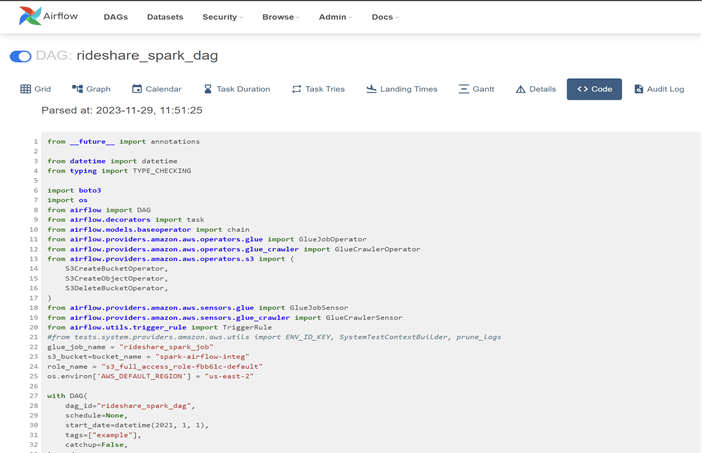
Our Spark-based data transformation is orchestrated through Airflow DAGs, enabling seamless integration into our existing infrastructure. This integration involves the initiation of two distinct workflows, each tailored to specific processing scenarios. The first workflow triggers a Spark job within AWS Glue, seamlessly extending Spark’s capabilities within our environment. This integration provides a streamlined approach to handling complex transformations, leveraging the distributed computing power of Spark while maintaining the orchestration simplicity offered by Airflow. The Glue based Spark job execution is shown in the below images:
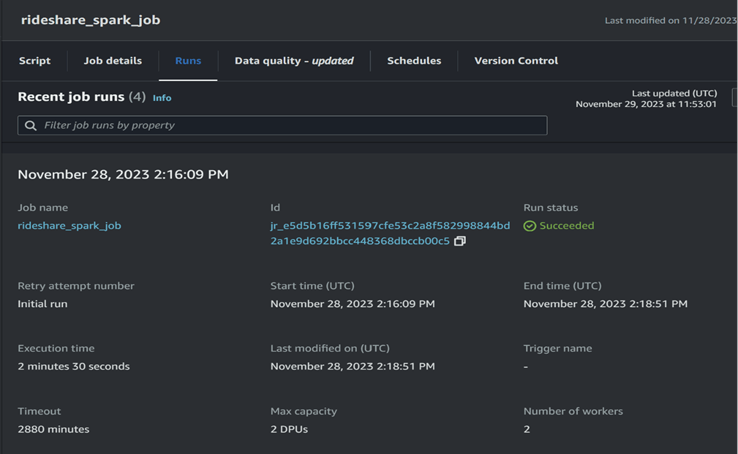
In addition to the Glue-based Spark integration, our platform embraces a serverless approach to Spark processing. The second workflow dynamically creates an EMR (Elastic MapReduce) serverless application, initiating the Spark job and efficiently terminating the application upon completion. This serverless approach not only optimizes resource utilization but also enhances the cost-effectiveness of our data processing pipeline. It ensures scalability without compromising efficiency. The below images show the EMR serverless spark job details:
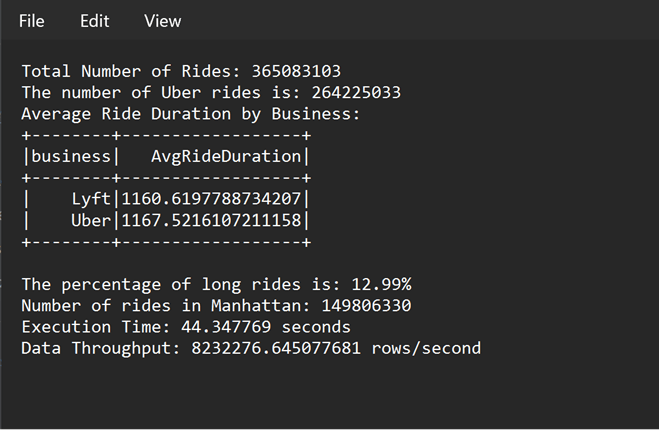
This image is the Output Text file obtained in the S3 bucket as logs for SPARK_DRIVER:
The coexistence of Spark within our transformation framework empowers our data engineers to tackle diverse data processing challenges with flexibility and efficiency. Whether we are leveraging Glue for a seamlessly integrated Spark experience or opting for a serverless EMR application, Spark plays a pivotal role in ensuring that our data transformation capabilities remain agile, scalable, and well-equipped to handle the evolving demands of our expanding data landscape.
Data Quality Check
Data Quality is not a destination but a continuous journey. It’s about maintaining the accuracy, consistency, reliability, and integrity of the data at every stage. Data Quality involves validation, testing, and documentation, ensuring that the data meets the expected standards and aligns with the quality benchmarks.
Great Expectations
Great Expectations is the guardian of data quality in the platform. It provides a powerful framework for automated testing and validation of data. Great Expectations ensures the integrity and reliability of data, whether by checking the accuracy of the golden-copy data or validating transformations. Acting as a quality assurance layer within the system, users can write suites provided by Great Expectations, creating components such as expectations and validations on the final golden-copy data in the Data Warehouse. Simply running a DAG pointing to these expectations each time new data is ingested allows for achieving reliable results.
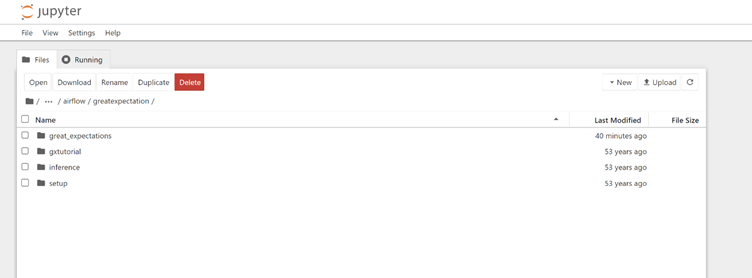
This image shows the folder structure of Jupyter Notebook setup of Great Expectations inside Airflow EC2 instance:
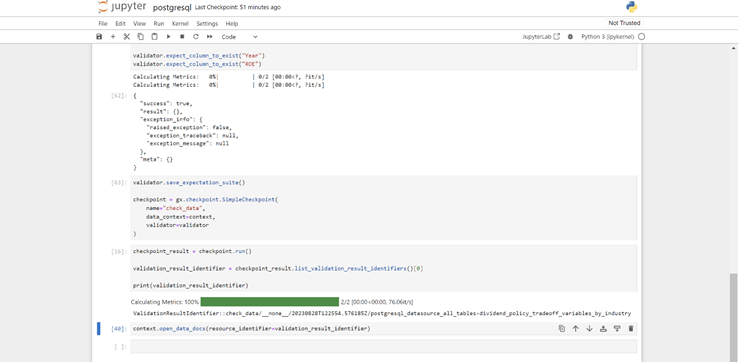
Below image shows the notebook which creates the expectations, validations and their checkpoints for the target data in Data Warehouse or Database:
Illustrative Use Cases
Finance
1. Algorithmic Trading: In fast-paced financial markets, rapid data analysis is essential for executing algorithmic trading strategies accurately. Modern data platforms provide low-latency data access and advanced analytics, offering traders a competitive edge.
2. Fraud Detection: Staying ahead of financial fraud requires real-time vigilance, which can be challenging. Modern data platforms offer robust tools for transaction monitoring, anomaly detection, and fraud prevention, strengthening security for businesses and clients.
Healthcare
1. Patient Outcomes Improvement: Predicting and improving patient treatment outcomes is vital in healthcare. Modern data platforms enable healthcare providers to analyze patient data, identify trends, and enhance care quality.
2. Drug Discovery Acceleration: Drug discovery involves processing massive datasets. Modern data platforms expedite this process by analyzing data efficiently, potentially leading to faster drug discoveries.
Legal
1. Contract Analysis: The legal industry grapples with the time-consuming task of contract analysis. Modern data platforms with NLP capabilities streamline this process, making it easier to assess contract terms, risks, and compliance.
2. Litigation Support: Legal cases involve vast amounts of data. Modern data platforms help organize and analyze this data, facilitating better legal strategies and decision support.
Manufacturing
1. Predictive Maintenance: Equipment downtime in manufacturing is costly. Modern data platforms predict maintenance needs by analyzing equipment data, reducing downtime, and optimizing operations.
2. Supply Chain Optimization: Modern data platforms analyze supply chain data to improve efficiency, reduce costs, and enhance product delivery, providing manufacturers with a competitive edge.
Insurance
1. Risk Assessment Enhancement: Assessing risk profiles accurately is crucial for insurance. Modern data platforms use data analytics to refine underwriting processes and provide more accurate risk assessments.
2. Claims Processing Automation: Automating claims processing with data-driven insights accelerates settlements and enhances the overall efficiency of insurance operations.
Benefits
Efficient Data Utilization: Harness the power of your data by efficiently integrating, transforming, and making it readily accessible. This leads to faster decision-making and a competitive edge.
Cost Savings: Optimize costs through efficient data workflows, scalability, and a cost-effective pricing model, ensuring your data operations are both effective and budget-friendly.
Futureproofing: The decoupled architecture allows you to adapt to evolving technologies seamlessly, ensuring your data infrastructure remains relevant and capable of meeting future needs.
Enhanced Data Quality: Elevate data quality through automated data cleaning and transformation processes, resulting in more reliable insights and decision support.
Community-Backed Open Source: Leverage the support and innovation of a robust developer community behind the open-source tools, providing you with ongoing resources and enhancements.
Conclusion
In conclusion, the Modern Data Platform is more than just a technological solution; it’s a vision realized. It embodies a future where data management is not just about handling vast quantities of information but doing so with agility, intelligence, and foresight. This platform empowers businesses to make informed decisions, optimize operations. And drive growth, setting new benchmarks in data processing and transformation. It’s not just a step forward; it’s a leap into the future of data excellence.
What sets this platform apart is its adaptability and precision. Every component is meticulously crafted, from leveraging Terraform for infrastructure creation to employing Airbyte, Airflow, and Superset for data ingestion, processing, and distribution. The automated handling of DAG files, DBT models, and Great Expectation suite files through a dedicated code-pipeline exemplifies the platform’s commitment to automation and accuracy.
Ready to unlock your data’s full potential and transform it into a strategic asset? Discover how our Modern Data Platform can revolutionize your capabilities. Get started on the path to empowerment today!

Digital Alpha Platforms, an AI and data firm headquartered in New York, is proud to be an AWS partner, delivering advanced data solutions. Our modern data platform, fully integrated with AWS services, empowers quants and data scientists alike. Whether you’re focused on risk assessment, refining trading strategies, or unearthing insights from vast datasets, explore the transformative capabilities of data analysis through AWS Marketplace or reach out to us directly.
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


