
In today’s data-driven world, proper data management is crucial for enterprise success, enabling organized, accessible, and reliable data for informed decision-making. Traditional centralized approaches, while functional, pose challenges like data silos and IT bottlenecks, particularly with increasing data volumes and diversity. Imagine a bank struggling with siloed data hindering risk assessment or an asset management firm navigating fragmented data in diverse markets. To address these challenges, enterprises are turning to data mesh architecture. This innovative approach prioritizes decentralization, domain-oriented ownership, and a collaborative data culture, empowering teams to effectively manage the growing volume, variety, and velocity of data.
Behind the Architecture
Decentralized Approach:
The main aspect of Data Mesh Architecture is its decentralized approach to data management. Domain teams take ownership of their data in a federated structure, dividing control throughout, instead of relying on a single team at the top of a centralized structure. Individual domain teams within an organization assume the responsibility of data ownership and governance specific to the roles they play. Domain experts compose them, possessing the contextual knowledge to manage and derive value from their specific data domains.
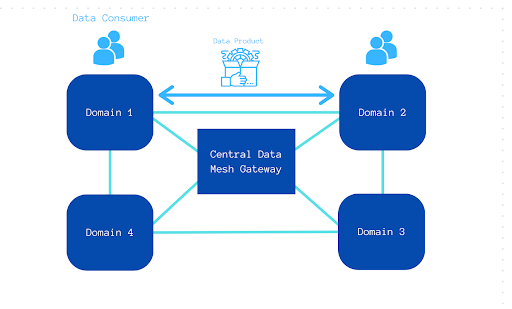
Team Roles:
- Domain Owner: They possess deep knowledge of their domain and takes ownership of it, defining data products, setting quality standards, and data governance practices.
- Data Product Managers: They work with the domain owner to define the development and features of data products.
- Data governance Specialists: They define the data governance policies, access controls, and privacy measures.
- Platform Teams: These are teams of different types of engineers that develop different parts of the technical infrastructure, tools, and services for data domain teams.
- Data Analysts: They analyze and derive insights from the data. They use this knowledge to work with domain teams in understanding and creating data models for analytics and reporting.
- Data Quality Teams: They maintain data quality and reliability in the domain, define data quality standards, implement data validation processes, and collaborate with domain owners to address data quality issues.
This structure helps enforce Data Mesh’s key benefits from decentralization to greater collaboration.
The Key Principles of Data Mesh
Three fundamental principles define the innovative data management approach of Data Mesh architecture.
- Domain-Oriented Ownership: The decentralized architecture is what allows each team to take responsibility for data products within their domain. They are free to control data quality, governance, and analytics. This empowerment fosters autonomy and accountability among teams, enabling them to make data-driven decisions and optimize data management processes tailored to their specific domain’s requirements. In the legal sector, domain-oriented ownership empowers individual practice areas within law firms to take charge of their data products. A litigation team can easily manage and curate case-related data in their domain.
- Self-Serve Infrastructure: The decentralized nature of Data Mesh allows for self-serve data infrastructure, enabling domain teams to independently manage their data products with the tools and capabilities provided. They have the freedom to choose the most suitable tools, platforms, and frameworks to ingest, process, and store data based on their domain’s unique needs. In asset management, firms manage various assets including equity, fixed income, and alternatives. Each investment team can leverage self-serve infrastructure to select the data tools and technologies tailored to their specific asset class.
- Product Thinking: The product-centric approach within data mesh is pivotal. Data is endowed with clear ownership, features, and documentation, undergoing continuous development. Treating data as a product ensures deliberate design, ongoing development, and enhancement. This mindset prioritizes user experience, enhancing data accessibility, comprehension, and reliability for stakeholders. For instance, an insurance company managing multiple coverage lines can treat each line as a distinct data product. This approach ensures that underwriting teams access comprehensive, well-structured data tailored to their specific insurance lines.
How it’s Different
The key distinction that sets data mesh architecture apart from traditional data architectures lies in its decentralized nature. In traditional data management structures, such as data warehouses and data lakes, data is centralized and managed by a single team. While these approaches can offer benefits like easier querying and faster access to raw data, they also present challenges.
- Data Warehouses: Data Warehouses consolidate data from various sources into a unified repository, facilitating analytical processing. The structured nature of data warehouses simplifies querying and reporting, enabling organizations to gain insights from their data efficiently. However, data warehouses can face limitations when dealing with diverse data types and formats, potentially requiring extensive preprocessing.
- Data Lakes: Data Lakes on the other hand, store raw, unstructured data in its original format, providing greater accessibility and flexibility. This allows organizations to store large volumes of data, both structured and unstructured, without immediate structuring or transformation. Yet, data lakes can become data swamps if not well-managed, leading to challenges in data discovery, quality assurance, and governance.
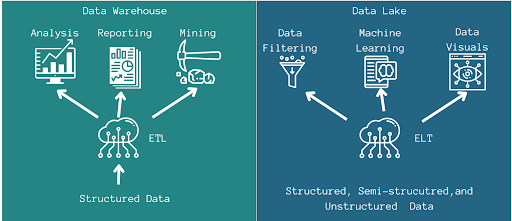
Limitations: However, centralized control in traditional structures can lead to bottlenecks and data silos. It can slow down data delivery, hamper collaboration, and limit the organization’s ability to fully leverage its data assets. Data mesh architecture addresses these challenges by breaking down centralized control and distributing data ownership among domain teams. By doing so, data mesh fosters collaboration, knowledge sharing, and innovation across the organization. It allows domain teams to develop their data products tailored to their unique needs, ensuring that data serves as a valuable asset rather than a rigid, siloed resource.
Takeaways
As organizations grapple with increasing data volumes and complexities, data mesh offers a path forward to optimize data management, harness the potential of data assets, and drive data-driven decision-making at all levels of the organization.
- Decentralized Architecture: Domain teams take ownership of their data, fostering and practicing autonomy and greater accountability. Silos are broken down data governance is made more efficient between specific domains
- Role-Based Ownership: Key roles are established to maintain the domain including Data Owners, Data Project Managers, Platform Teams, and more.
- Domain-Oriented Empowerment: Teams are able to make data-driven decisions tailored to their specific needs.
- Self-Serve Infrastructure: Teams choose the tools and infrastructure that best serve their needs.
- Product-Centric Mindset: Domains treat data like a product, emphasizing features, ownership, and continuous improvements.
Are you ready to unlock the full power of your data? Embrace data mesh and empower your teams with domain-oriented ownership, self-serve infrastructure, and a product mindset. Additionally, by fostering a culture of data ownership and collaboration at your organization, you can effectively navigate complex data landscapes in today’s digital era. Whether you’re considering embracing data mesh or not, utilizing this approach can revolutionize the way you manage and leverage your data today!


