
Background
Every investor who has invested or considered investing in risky assets at some point has thought about the most they can lose on the investment. Value at Risk (VAR) provides some answers to this with a certain probability. VAR is one of the quantitative methods used in banking and insurance to estimate the largest loss that can occur with a prescribed probability in the future. Investors make financial investment decisions based on three criteria: return, risk, and liquidity. Risk managers and analysts have to deal with vast volumes of data for risk evaluation and assessment to optimize the portfolio. According to Statista, the mass volume of data created, stored, copied, and consumed in 2020 was over 64 zettabytes (ZB), or about 64 trillion gigabytes (GB). This is expected to rise to 181 ZB by the year 2025.
The Challenge
The financial services sector is the most data-intensive sector in the global economy. They heavily invest in data collection and processing complex data sets to make investment decisions. Analysis and prediction of this data require them to create data lakes using multiple open-source tools like apache spark, hudi, etc., and massive computational power. Although popular with big financial institutions, VAR comes with certain challenges and limitations.
Some of the key challenges for VAR calculations are as follows:
False sense of security: Looking at risk exposure in terms of VAR can be very misleading. Many people think of VAR as “the most I can lose,” especially when it is calculated with the confidence parameter set to 99%.
Subjectivity: 99% percent VAR means that in 1% of cases, the loss is expected to be greater than the VAR amount. Value At Risk does not say anything about the size of losses within this 1% of trading days and by no means does it say anything about the maximum possible loss. The worst-case loss might be only a few percent higher than the VAR, but it could also be high enough to liquidate a company.
Difficult calculation for large portfolios: While calculating the VAR of a portfolio, one needs to estimate or measure not only the return and volatility of individual assets but also the correlation between them. The task becomes increasingly difficult with the growing number and diversity of positions in the portfolio.
VAR is not additive: The VAR of a portfolio containing assets X and Y does not equal the sum of VAR of asset X and VAR of asset Y.
Quality of output depends on input and assumptions: A common mistake with using the classical variance-covariance VAR method is assuming a normal distribution of returns for assets and portfolios with non-normal skewness or excess kurtosis. Using unrealistic return distributions as inputs can lead to underestimating the real risk with VAR.
Inconsistent Results: Different approaches to VAR calculation – classical variance-covariance parametric VAR, historical VAR, or Monte Carlo, leads to very different results with the same portfolio, so the representativeness of VAR can be questioned.
There are a few technical challenges as well for businesses in the process of VAR calculation:
- For businesses to set up an EMR infrastructure, they need to install all the required hardware and provide network connectivity with each of them.
- The cost of maintaining the infrastructure is high. Organizations need dedicated resources who can work as big data analysts or have knowledge of setting up EMR-Spark clusters.
- Resources get wasted because not every day organizations need this high computation power.
Digital Alpha brings in its data platform using Amazon EMR for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications.
Solution
The goal is to implement a CI/CD solution that automates the provisioning of EMR cluster resources and performs ETL jobs directly. The EMR solution was built through CDK, Step Functions Workflow, and AWS Lambda.
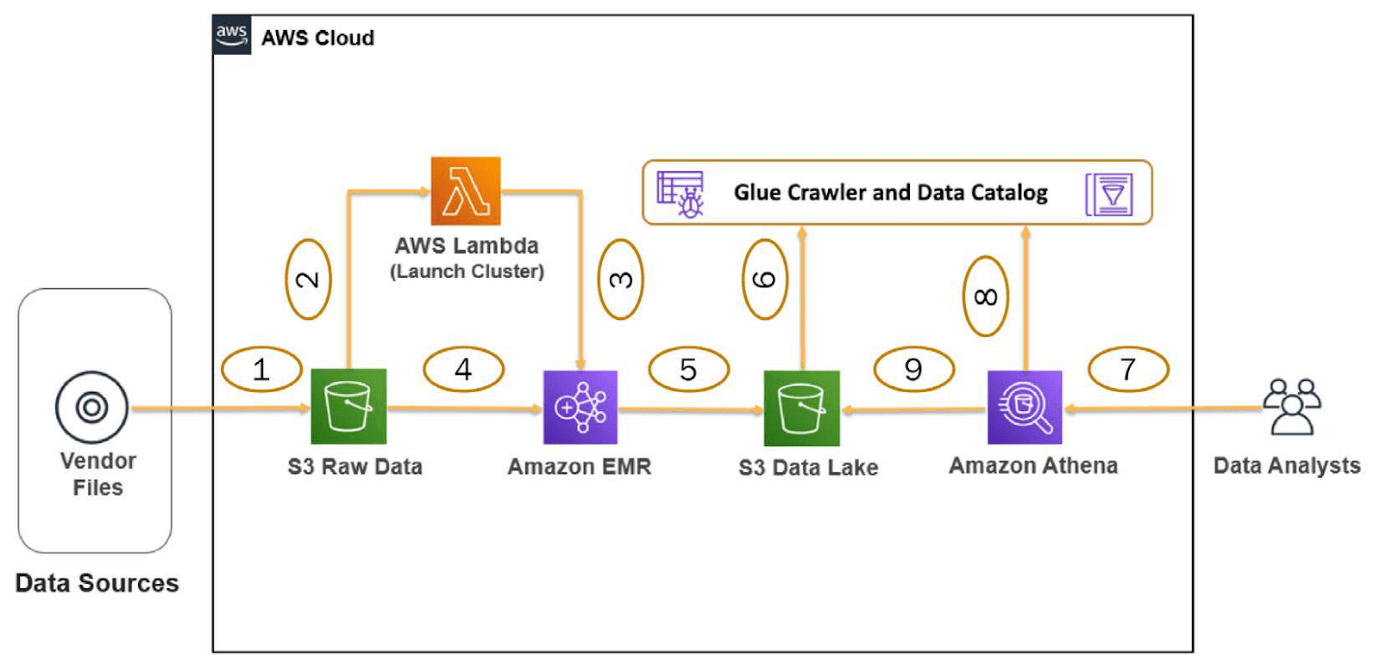
An input bucket is created where developers can update the raw input data in CSV format. The file modification will trigger the lambda function, which is used to create a new EMR cluster.
Within the EMR cluster, an auto-scaling policy has been used to increase the instances as the workload increases.
ML instances and on-demand instances are used that can be configured by default.
These clusters are launched with pre-configured security groups, so it doesn’t require manually updating the inbound-outbound rules. After cluster creation, it performs the basic ETL operation described in the spark -step using the spark py script.
The output of the files is then stored in the output bucket in parquet format.
A Glue Data Catalog table can be created on top of the S3 data using Glue Crawler. To validate the output, a query is run in Athena.
Benefits
- Amazon EMR pricing depends on the instance type, the number of Amazon EC2 instances deployed, and the Region in which the cluster is launched. On-demand pricing offers low rates, but reduce the cost can be reduced further by purchasing Reserved Instances or Spot Instances. Spot Instances can provide significant savings—as low as a tenth of on-demand pricing in some cases.
- Amazon EMR integrates with other AWS services to provide capabilities and functionality related to networking, storage, security for a cluster. The following list provides several examples of this integration:
- Amazon EC2 for the instances that comprise the nodes in the cluster
- Amazon Virtual Private Cloud (Amazon VPC) to configure the virtual network in which you launch your instance
- Amazon S3 to store input and output data
- Amazon CloudWatch to monitor cluster performance and configure alarms
- AWS Identity and Access Management (IAM) to configure permissions
- AWS CloudTrail to audit requests made to the service
- AWS Data Pipeline to schedule and start the clusters
- AWS Lake Formation to discover, catalog, and secure data in an Amazon S3 data lake
- Amazon EMR provides flexibility to scale the cluster up or down as the computing needs change. The cluster can be resized to add instances for peak workloads and remove instances to control costs when peak workloads subside.
- Amazon EMR monitors nodes in the cluster and automatically terminates and replaces an instance in case of failure.
- Amazon EMR provides configuration options that control if a cluster is terminated automatically or manually. If a cluster is configured to be automatically terminated, it is terminated after all the steps are complete. This is referred to as a transient cluster.
Businesses have major advantages of using VAR:
- Investment professionals, banks, or any financial institution can summarize all risks associated with a portfolio into a single number.
- Consistent measure of risks across all financial institutions trading activities.
- Can compare a large variety of financial instruments and portfolios
- Considers interrelationships between different risk factor
- Can be measured in price units and as a percentage of portfolio value
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


