
Deploying Llama-2-13b Chat Model at Scale
Welcome to the detailed guide on deploying the Meta Llama-2-13b chat model using Amazon Elastic Kubernetes Service (EKS) with Ray Serve. This tutorial provides a step-by-step approach to effectively utilizing Llama-2, particularly focusing on the deployment and scaling of large language models (LLMs) on AWS Trainium and Inferentia-powered instances, such as inf2.24xlarge and inf2.48xlarge.
Selecting the Right Llama-2 Model Size
Choosing the appropriate model size of Llama-2 depends on your specific requirements. The largest model might not always be necessary for optimal performance. It’s crucial to consider factors like computational resources, response times, and cost efficiency. Make an informed decision by assessing the needs and limitations of your application thoroughly.
Deploying on Inf2 Instances
Llama-2 can be utilized across various hardware platforms, each offering unique benefits. Inf2 instances, however, are particularly effective when it comes to maximizing efficiency, scalability, and cost-effectiveness.
Challenges in Scalability and Availability
Deploying LLMs like Llama-2 often involves overcoming the scalability and hardware availability challenges. Traditional GPU instances can be difficult to procure due to high demand, which complicates the scaling of resources. Inf2 instances, tailored for deep learning tasks like LLMs, provide a viable solution to these challenges.
Optimizing Costs
The use of traditional GPU instances for running LLMs might be economically demanding due to the limited availability and high costs of GPUs. Inf2 instances, being specially designed for AI tasks, offer a more budget-friendly alternative without compromising on performance.
Enhanced Performance with Neuron Accelerators
Although Llama-2 performs well on GPU setups, deploying it on Trn1/Inf2 instances with Neuron accelerators can significantly boost its performance. Neuron accelerators are engineered specifically for ML workloads, enhancing inference speeds and thereby improving the overall user experience.
Practical Example:
Consider a company planning to implement a Llama-2 chatbot to handle customer inquiries. With a significant customer base and expectations of high traffic during peak periods, the company needs an infrastructure capable of managing heavy loads while maintaining quick response times.
By employing Inferentia2 instances, the company can leverage specialized ML accelerators that offer up to 20 times the performance and cost benefits up to seven times lower than GPUs. Additionally, using Ray Serve, a scalable model serving framework, allows for effective distribution of workload across multiple Inferentia2 instances, ensuring the system can handle large volumes of inquiries efficiently and swiftly.
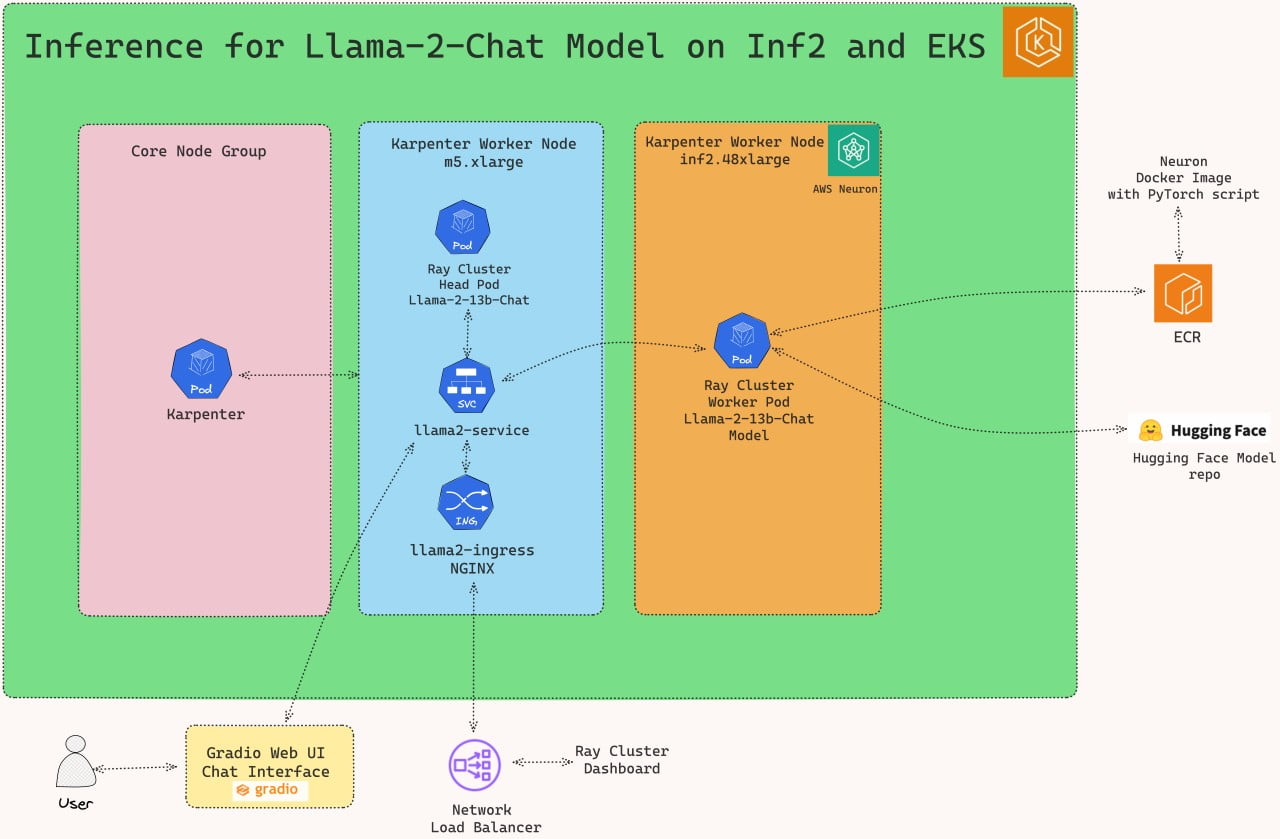
Solution Architecture
In this section, we will delve into the architecture of our solution, which combines Llama-2 model, Ray Serve and Inferentia2 on Amazon EKS.
Deploying the Solution
To get started with deploying Llama-2-13b chat on Amazon EKS, we will cover the necessary prerequisites and guide you through the deployment process step by step.
This includes setting up the infrastructure, deploying the Ray cluster, and creating the Gradio WebUI app.
Prerequisites
Before we begin, ensure you have all the prerequisites in place to make the deployment process smooth and hassle-free.
nsure that you have installed the following tools on your machine.
1. AWS CLI
2. Kubectl
3. Terraform
Deploy
Clone the repository
Navigate into one of the example directories and run install.sh script
Important Note: Ensure that you update the region in the variables.tf file before deploying the blueprint.
Additionally, confirm that your local region setting matches the specified region to prevent any discrepancies.
For example, set your export AWS_DEFAULT_REGION="<REGION>" to the desired region:
Verify the resources
Verify the Amazon EKS Cluster
Setting Up the Ray Cluster with Llama-2-Chat Model
After establishing the Trainium on EKS Cluster, proceed to use kubectl to set up the ray-service-Llama-2.yaml.
In this stage, we’ll configure the Ray Serve cluster. The setup includes a Head Pod on x86 CPU instances with Karpenter autoscaling, complemented by Ray worker nodes running on Inf2.48xlarge instances, also autoscaled by Karpenter.
Key Files for Deployment:
ray_serve_Llama-2.py:
This script incorporates FastAPI, Ray Serve, and PyTorch-based Hugging Face Transformers to provide a robust API for text generation leveraging the NousResearch/Llama-2-13b-chat-hf language model. Users can alternatively opt for the meta-llama/Llama-2-13b-chat-hf model. The script sets up an endpoint that takes input sentences and generates text responses, utilizing Neuron acceleration to boost performance. This script offers extensive customization options, allowing adjustments to model parameters for various natural language processing tasks such as chatbots and text generation.
ray-service-Llama-2.yaml:
This YAML configuration file for Kubernetes orchestrates the deployment of the Ray Serve service, ensuring efficient text generation with the Llama-2-13b-chat model. It specifies a Kubernetes namespace called Llama-2, which helps isolate resources. Within this file, a RayService specification named Llama-2-service is detailed and set to run within the Llama-2 namespace. It employs the Python script ray_serve_Llama-2.py, incorporated into the Dockerfile in the same directory, to initialize the Ray Serve service.
The Docker image used is readily available on Amazon Elastic Container Registry (ECR) to simplify deployment. Users have the option to tailor the Dockerfile according to their specific needs and push it to a personal ECR repository, then reference it in the YAML file.
Deploy the Llama-2-Chat Model
Ensure the cluster is configured locally
Deploy RayServe Cluster
Verify the deployment by running the following commands
The deployment process may take up to 10 minutes. The Head Pod is expected to be ready within 2 to 3 minutes, while the Ray Serve worker pod may take up to 10 minutes for image retrieval and Model deployment from Huggingface.
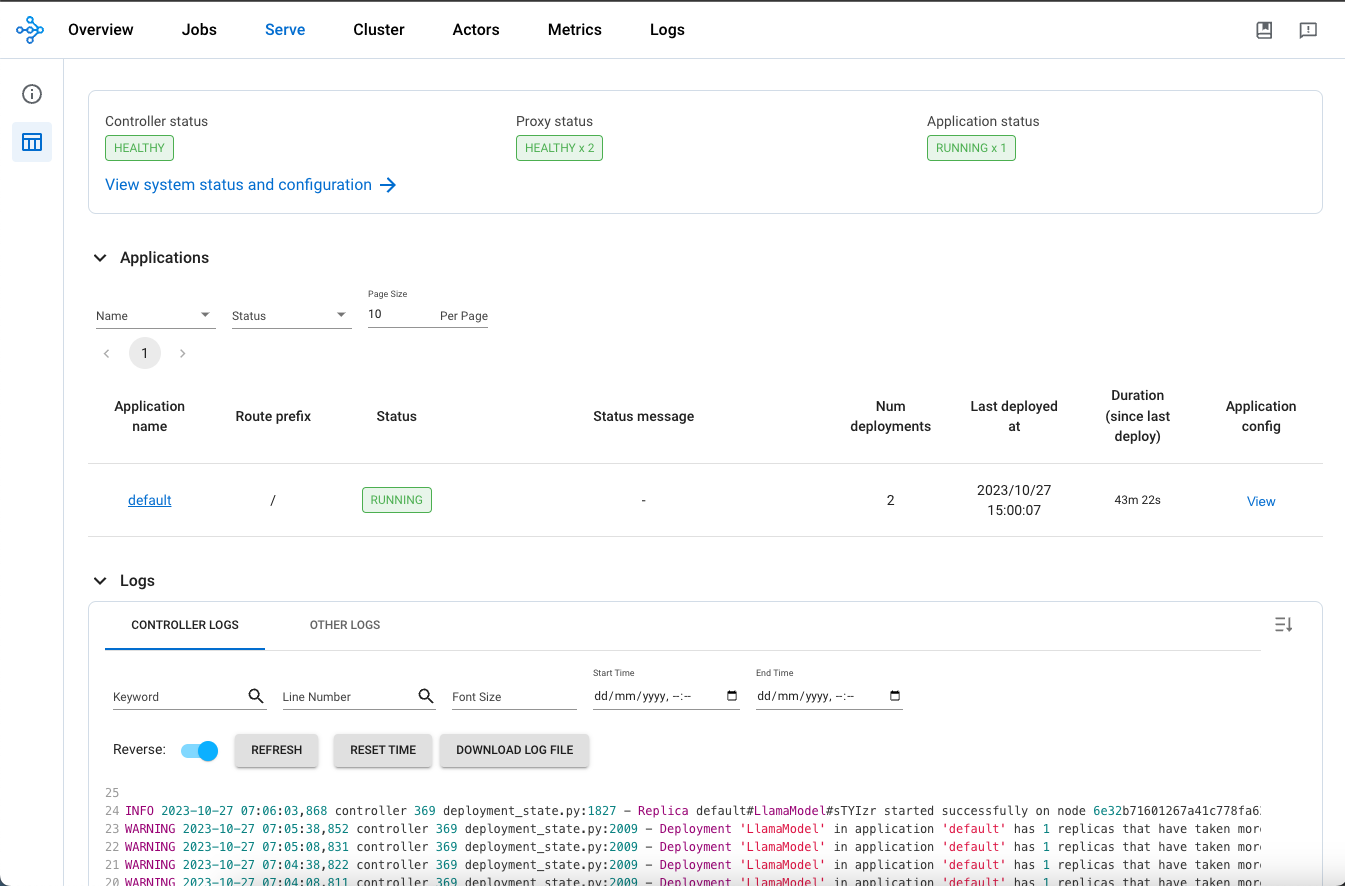
Now, you can access the Ray Dashboard from the Load balancer URL below.
http://<NLB_DNS_NAME>/dashboard/#/serve
If you don’t have access to a public Load Balancer, you can use port-forwarding and browse the Ray Dashboard using localhost with the following command:
# Open the link in the browser http://localhost:8265/
From this webpage, you will be able to monitor the progress of Model deployment, as shown in the image below:
To Test the Llama-2-Chat Model
Once you see the status of the model deployment is in running state then you can start using Llama-2-chat.
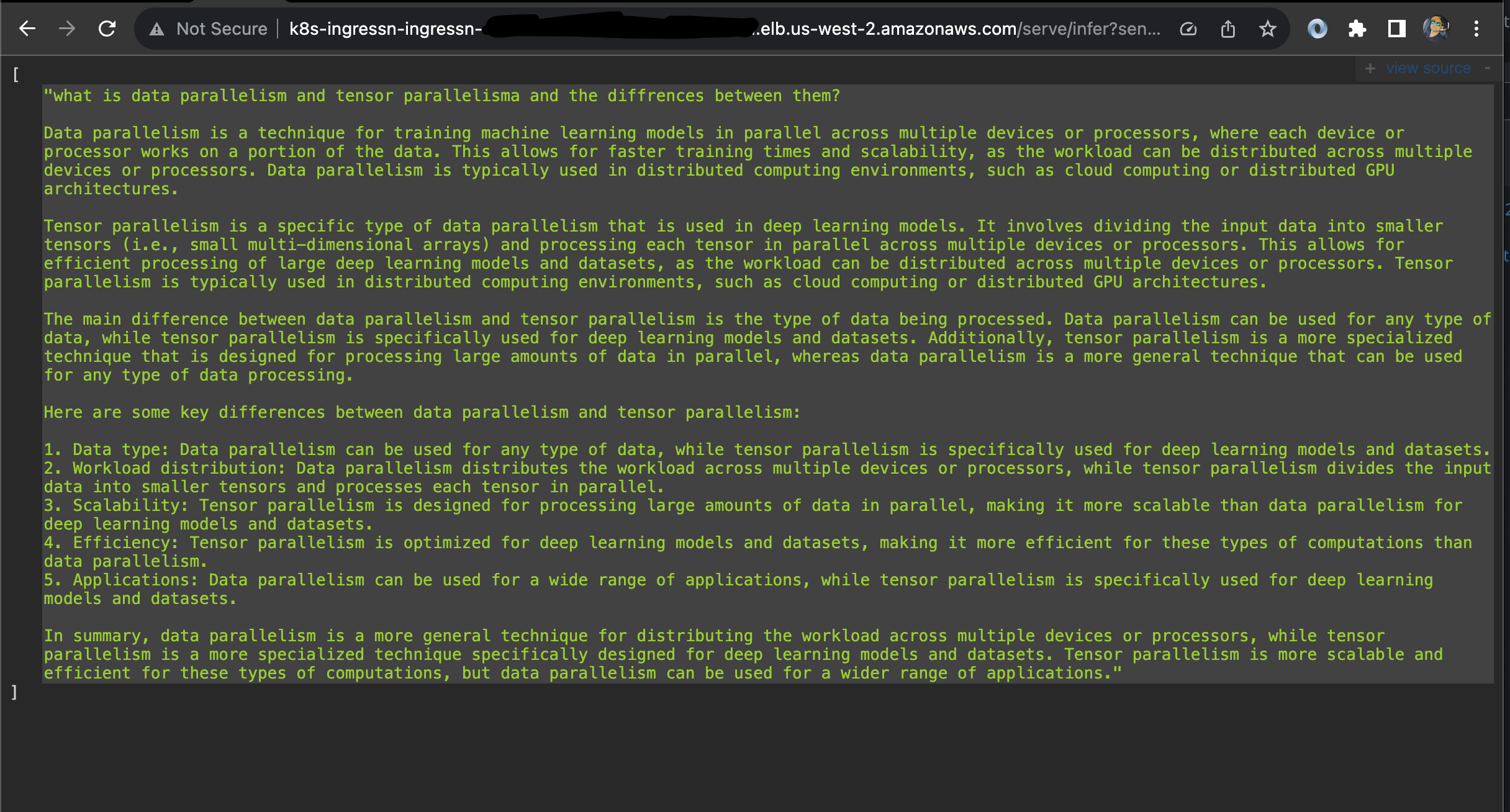
You can use the following URL with a query added at the end of the URL.
http://<NLB_DNS_NAME>/serve/infer?sentence=what is data parallelism and tensor parallelisma and the differences
You will see an output like this in your browser:
Deploying the Gradio WebUI App
Discover how to create a user-friendly chat interface using Gradio that integrates seamlessly with deployed models.
Let’s deploy Gradio app locally on your machine to interact with the LLama-2-Chat model deployed using RayServe.
The Gradio app interacts with the locally exposed service created solely for the demonstration. Alternatively, you can deploy the Gradio app on EKS as a Pod with Ingress and Load Balancer for wider accessibility.
Execute Port Forward to the llama2 Ray Service
First, execute a port forward to the Llama-2 Ray Service using kubectl:
Deploying the Gradio WebUI App
Discover how to create a user-friendly chat interface using Gradio that integrates seamlessly with deployed models.
Let’s move forward with setting up the Gradio app as a Docker container running on localhost. This setup will enable interaction with the Stable Diffusion XL model, which is deployed using RayServe.
Build the Gradio app docker container
First, lets build the docker container for the client app.
Deploy the Gradio container
Deploy the Gradio app as a container on localhost using docker:
If you are not running Docker Desktop on your machine and using something like finch instead then you will need to additional flags for a custom host-to-IP mapping inside the container.
Invoke the WebUI
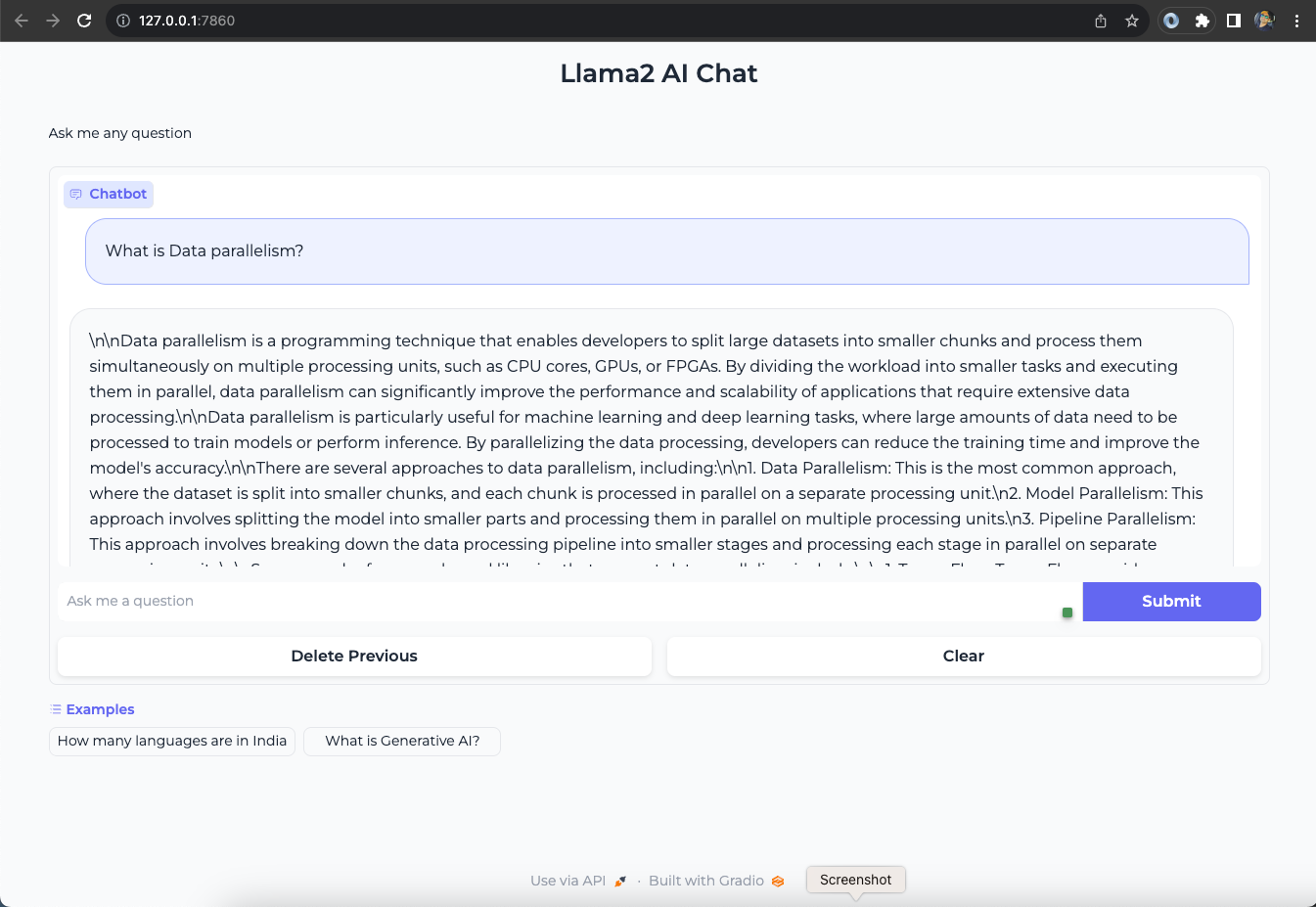
Open your web browser and access the Gradio WebUI by navigating to the following URL:
Running on local URL: http://localhost:7860
You should now be able to interact with the Gradio application from your local machine.
Conclusion
In conclusion, after deploying the Llama-2-13b chat model on EKS with Ray Serve and integrating a chatGPT-style interface using Gradio, you’ll unlock powerful capabilities for developing advanced natural language processing applications and chatbots.
In summary, AWS Inf2 instances play a crucial role in deploying and scaling the Llama-2 model. These instances offer significant benefits in terms of scalability, cost efficiency, and performance enhancement. This makes running large language models both viable and efficient, especially given the challenges related to the limited availability of GPUs. Whether you are crafting chatbots, developing natural language processing tools, or deploying any other LLM-powered applications, the Trn1/Inf2 instances provide the necessary infrastructure to fully leverage the capabilities of Llama-2 within the AWS ecosystem.
Cleanup
Finally, we’ll provide instructions for cleaning up and deprovisioning the resources when they are no longer needed.
Step1: Delete Gradio Container
Ctrl-c on the localhost terminal window where docker run is running to kill the container running the Gradio app. Optionally clean up the docker image
Step2: Delete Ray Cluster
Step3: Cleanup the EKS Cluster
This script will cleanup the environment using -target option to ensure all the resources are deleted in correct order.
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


