
In the era of large language models (LLMs), exemplified by GPT-3.5, the ability to generate remarkably human-like text has reached unparalleled heights. Yet, this newfound capability carries the weighty responsibility of protecting sensitive information, echoing the prevailing concerns of our digital age—privacy and data security. Within this context, harnessing AI’s potential through custom AI-LLM training on proprietary data, such as enterprise internal knowledge bases, emerges as a promising strategy. It promises to augment privacy safeguards while capitalizing on the capabilities of advanced language models. In this blog post, we will embark on a journey through the intricacies of data curation, the use of more expansive models for this purpose, and the training of new models. Together, we will shed light on how this approach fortifies privacy in the realm of AI-LLM models.
Data Extraction
The process of constructing a custom model begins with data collection, an initial step that demands meticulous attention. It entails the judicious selection and meticulous data preparation to serve as the foundation for training the ai- LLM. Several pivotal considerations shape this phase:
Data Source Selection: Commence by identifying the wellspring of data housing the pertinent information requisite for your purpose. Potential sources span proprietary company documents, customer interactions, and other invaluable textual resources, including data obtained from web scraping endeavors.
Anonymization: A crucial step involves expunging or anonymizing personally identifiable information (PII) or other sensitive data. By doing so, you guarantee that the trained Ai-llm model remains incapable of inadvertently producing private or sensitive information.
Data Augmentation: An instrumental technique for elevating model performance and preserving privacy involves data augmentation. This method entails generating novel data points, mirroring the structure and content of your original dataset.
For instance, consider training an ai-LLM designed to assist enterprise data assistants in efficiently handling information requests from diverse corporate departments. In this context, data extraction might encompass aggregating information from various sources like company reports, internal memos, and structured databases. This approach ensures the data’s richness and relevance to the model’s intended application.
Enhanced Data Curation with GPT-4
When considering the curation of data, particularly for training an LLM, the choice of the right tools and techniques is paramount. Leveraging a more advanced LLM like GPT-4 can offer several key advantages in this endeavor:
Content Filtering: Harness the power of GPT-4 to implement robust content filtering. By using a model with a profound understanding of language, you can swiftly identify and exclude text passages that may pose privacy risks. This step is pivotal in safeguarding sensitive or confidential information within your dataset.
Content Summarization: GPT-4’s natural language processing capabilities can be employed to summarize extensive documents or articles. This serves a dual purpose—reducing the exposure of sensitive information during the curation process and making the data more manageable and concise.
Data Transformation: Transforming data from various sources, such as web articles and PDFs, into a structured query and response format is made efficient with the aid of a larger model. This transformation not only readies the data for training but also ensures its compatibility with the target model.
By employing a more potent model during the curation process, you significantly mitigate the risk of inadvertently exposing sensitive data. Moreover, you streamline the data into a format that is both usable and effective for training purposes.
Practical Application: Curating Data for a Tax Model with GPT-4
To illustrate the real-world application of leveraging GPT-4 in data curation, let’s consider a scenario where you prepare data for a Tax model. In this case, GPT-4 is central in transforming the scraped data into a structured question-and-answer format. The process involves presenting the model with an article and a prompt, instructing it to generate all possible question-and-answer pairs from the content. This curated dataset is the foundation for training and testing the Tax model.
By adopting this approach, you not only enhance the privacy and quality of the training data but also streamline the curation process, making it more efficient and effective.
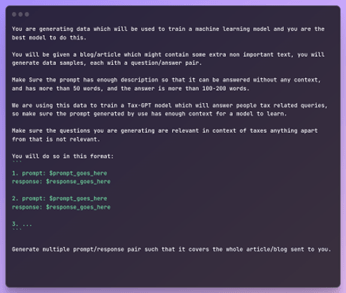
We use the above System Message for creation and then create prompts using this function
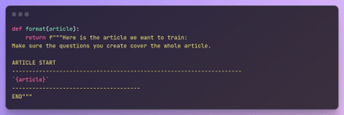
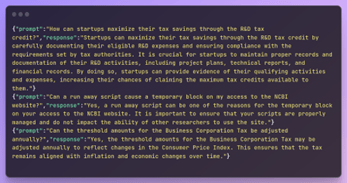
In the end, we get our data in the desired format:
Training the New Model on an EKS Cluster
Once you’ve meticulously curated your data using a robust LLM and transformed it into the ideal format, the next critical step is to train your custom Language Model. In this journey, harnessing the power of Amazon Elastic Kubernetes Service (EKS) clusters can be a game-changer, offering many advantages that streamline the training process and enhance its efficiency.
Advantages of Using Amazon EKS for Custom AI- LLM Training
Scalability: Amazon EKS clusters provide a scalable infrastructure that can be effortlessly adjusted to meet the dynamic computational requirements of training a language model. This flexibility enables you to allocate resources precisely tailored to your unique training needs efficiently.
Resource Management: EKS simplifies the complex resource management task, allowing for efficient allocation of GPU resources and other accelerators used in training. This optimization not only enhances training performance but also facilitates efficient parallel processing during model training.
Comprehensive Guides for Custom AI-LLM Training on Amazon EKS
To guide you through the process of training your custom Language Model on Amazon EKS, we recommend referring to the following comprehensive resources:
Using Trainium Chipset:
Learn to leverage the Trainium chipset, a cutting-edge AI accelerator, for your custom LLM training. This resource provides detailed insights into harnessing Trainium’s power on Amazon EKS.
AWS Trainium on EKS
Using GPUs:
Explore the utilization of GPUs for deploying generative AI models on Amazon EKS. This guide offers valuable information on optimizing GPU resources for your specific LLM training needs.
Deploy Generative AI Models on Amazon EKS
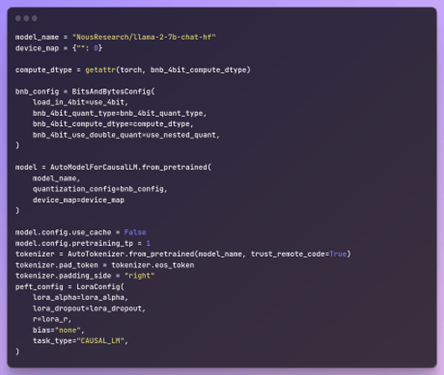
For training the Tax-Model we are Lora Training on a LLAMA-2 based model:
Enhanced Data Privacy: A Customized Approach to Protecting Sensitive Information
In the era of large language models (AI-LLMs), safeguarding sensitive information is of paramount importance. When considering the use of LLM providers for handling such data, it becomes crucial to acknowledge the inherent risks. By entrusting your sensitive information to these providers, you grant them access to potentially confidential and valuable data. This section delves into the significant concerns surrounding security and privacy when opting for LLM providers and highlights a safer, more customizable alternative.
Click here to read more about custom AI
Risks Associated with AI LLM Providers
Data Utilization Rights: LLM providers often retain the right to use the data you share for the ongoing training and refinement of their models. This practice opens the door to potential data exposure and compromises the confidentiality of your information.
Security Vulnerabilities: The security of your sensitive data becomes a potential concern in the event of a breach or compromise within the LLM provider’s systems. Data leaks and other security incidents could result from such vulnerabilities.
External Cyberthreats: AI-LLM providers themselves are not immune to cyberattacks. If malicious actors target their systems, your sensitive information stored on their servers becomes vulnerable to theft, adding an additional layer of risk.
Custom Data Handling Solutions
The solution lies in custom data handling approaches that empower you with greater control and security:
Data Retention: With custom data solutions, sensitive data never leaves your secure data warehouses. You maintain full control, significantly reducing the risk of unauthorized access or exposure.
Isolated Environments: Interactions with the language model occur within your personal Virtual Private Cloud (VPC), ensuring isolation and heightened security. The model operates within your controlled environment, offering robust protection against external threats and accidental data sharing.
By adopting custom data handling solutions, you can fortify the security of your sensitive data, mitigate the risk of privacy breaches, and confidently harness the power of large language models without compromising confidentiality or data integrity.
Conclusion
Custom AI-LLM training, fueled by proprietary data and advanced models, and fortified by the capabilities of EKS clusters, emerges as a formidable solution for augmenting privacy in the realm of natural language processing. This approach empowers organizations to harness state-of-the-art language models while vigilantly safeguarding sensitive information. In a world where data privacy concerns are escalating, the adoption of such practices is no longer a choice; it’s a necessity for the responsible and secure development of AI.
About Digital Alpha
Digital Alpha partners with RIAs, broker-dealers, and wealth management firms to design and implement technology strategies that drive operational efficiency and enable growth. Our integration-first methodology grounded in the 2025 Kitces research ensures that AI and automation investments deliver measurable results. Programs available for firms from $500M to $20B+ AUM, with production-ready implementations in 30–90 days.
Learn more: digital-alpha.com/capital-markets


